Схемное решение УРР
Схемное решение УРР
Демонстрационная схема выполнена на ИС HM2007, включенной в режим ручной моды. В данной моде для программирования ИС HM2007 используется микрофон и простейшая клавиатура.
Клавиатура
В качестве клавиатуры использована стандартная телефонная клавиатура, имеющая 12 нормально разомкнутых кнопок.
При включении питания ИС HM2007 осуществляет тестирование «бортовой» статической ОП. После завершения тестирования зажигаются цифры «00» на бортовом семисегментном индикаторе, зажигается красный светодиод, и устройство ожидает подачи команды.
Обучение
Нажмите «1» (на индикаторе загорится «01»), и светодиод погаснет. Затем нажмите «Т» (Training – обучение), и светодиод загорится снова.
Держите микрофон поближе ко рту и произнесите ключевое (обучающее) слово. Допустим, в качестве обучающего слова используется слово «компьютер». Произнесите «компьютер» в микрофон. Если устройство воспримет слово, то это вызовет мигание светодиода. Слово компьютер запрограммировано как слово под номером «01». Теперь если УРР «услышит» слово «компьютер», то оно отобразит число «01» на индикаторе.
Если диод не будет мигать после произнесения слова «компьютер», то либо попробуйте повторить это слово громче, либо начните сначала – наберите «01» а затем «Т».
Продолжайте введение образцов новых слов в УРР. Для второго слова нажмите «02» и затем «Т». Напомню, что устройство способно запомнить 40 слов. Понятно, что нет необходимости вводить все 40 слов. Введите необходимое вам количество слов и перейдите к следующему этапу.
Проверка функции распознавания
Произнесите одно из ранее запомненных слов в микрофон. На цифровом индикаторе должен высветиться соответствующий номер. Допустим, ключевое слово «директория» было введено под номером 25. Соответственно, произнесение слова «директория» должно вызвать зажигание цифры 25 на цифровом индикаторе.
Коды ошибок
• 55 = слишком длинное слово
• 66 = слишком короткое слово
• 77 = соответствующего слова не найдено
Очистка памяти
Вы можете удалять отдельные записи ключевых слов путем набора номера слова и кнопки CLR. Для полной очистки памяти необходимо набрать 99 и кнопку CLR.
Особенности ИС HM2007
ИС HM2007 для распознавания речи представляет собой однокристальную ИС КМОП-структуры высокой степени интеграции. В ИС имеется аналоговый вход, анализатор голоса, блок распознавания и блок контроля системных функций. ИС может использоваться самостоятельно или под управлением ЦПУ.
Характеристики
• Однокристальная ИС для распознавания речи КМОП-структуры высокой степени интеграции
• Распознавание речи конкретного источника
• Поддержка внешней ОП
• До 40 распознаваемых ключевых слов
• Максимальная длина слова 1,92 с
• Возможность подключения микрофона
• Возможность работы в ручной моде и под управлением ЦПУ
• Время реагирования менее 300 мс
• Напряжение питания 5 В
Конструкция устройства
Устройство РР можно изготовить на основе готового набора деталей, поставляемого Images Company (см. список деталей в конце этой главы). Принципиальная схема приведена на рис. 7.1. Монтаж деталей удобно осуществлять на печатной плате.

Рис. 7.1. Схема устройства распознавания речи
Припаяйте выводы клавиатуры к печатной плате согласно рис. 7.2. Клавиатура имеет семь проводников, которые соединяются с ИС HM2007 на печатной плате. Каждый вывод клавиатуры соотносится с соответствующим выводом ИС HM2007.
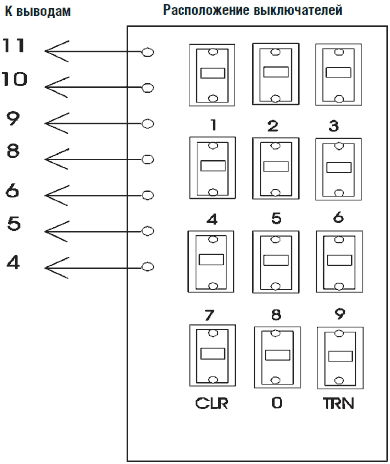
Рис. 7.2. Распайка клавиатуры для УРР
На рис. 7.3. изображено расположение деталей на печатной плате со стороны компонентов. На рис. 7.4 изображено УРР в сборе.
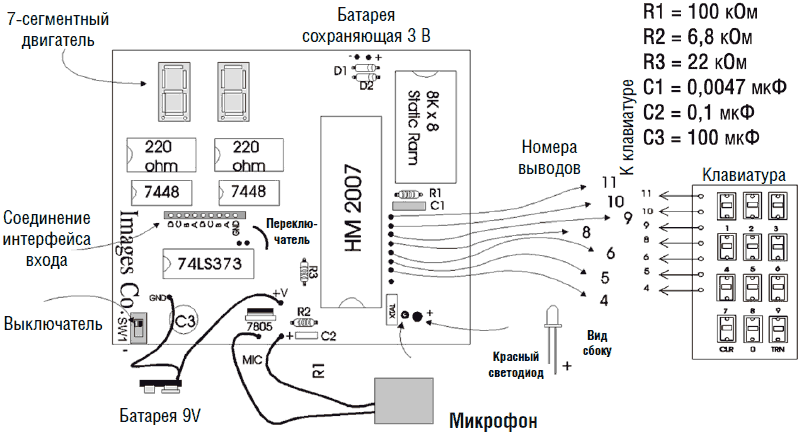
Рис. 7.3. Вид сверху расположения деталей на печатной плате

Рис. 7.4. Устройство РР в сборе
Устройство РР, независимое от говорящего
Демонстрационная схема УРР позволяет производить эксперименты по распознаванию речи как в зависимости, так и независимо от говорящего. Обычно система настраивается под конкретного человека в предположении, что он будет ее использовать.
Мы можем использовать другой способ и «обучить» систему реагировать относительно независимо от говорящего. Для достижения этой цели мы будем использовать четыре модели «обучения» для каждого командного ключевого слова.
Для упрощения последующей цифровой обработки сообщений используем следующую логику. Для обозначения ключевого слова мы будем использовать только первую цифру (младший разряд) на цифровом индикаторе.
Таким образом, модели «01», «11», «21» и «31» будут распознаваться как одно и то же ключевое слово. Поскольку учитывается только младший разряд, то во всех случаях распознаваемое слово будет обозначаться как «1». Аналогично, модели «04», «14», «24» и «34» будут соответствовать ключевому слову «4».
Проблемы могут возникнуть при распознавании кодов ошибок.
• 55 = слишком длинное слово
• 66 = слишком короткое слово
• 77 = соответствующего слова не найдено
В использованной логике эти коды будут интерпретироваться как ключевые слова «5», «6» и «7» соответственно. Для решения проблемы существуют два пути. Первый способ использует специальную логическую схему (см. рис. 7.5), которая выдает сигнал высокого уровня при появлении цифр 5, 6 или 7 в старшем разряде, который является сигналом блокировки. Такая схема выдает сигнал высокого уровня на линию при появлении цифр 5,6 или 7, который интерпретируется интерфейсом как сигнал запрета. Другой путь решения проблемы предполагает использование PIC микроконтроллера для чтения 8-разрядного кода с выхода УРР. Любое значение более 40 будет интерпретироваться как ошибка и соответственно игнорироваться. Мы не приводим здесь схемы интерфейса для PIC микроконтроллера, поскольку для любого, умеющего работать с PICBASIC программатором и PIC ИС (см. гл. 6), это не составит большого труда. В гл. 15 мы используем встроенный PIC в схеме УРР, используемого в устройстве управления рукой робота.
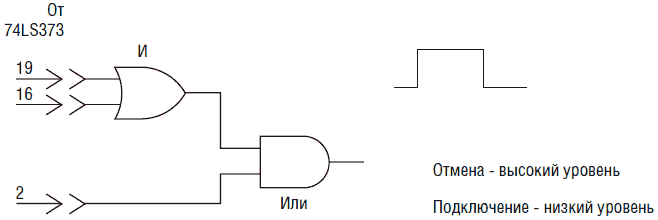
Рис. 7.5. Детектор ошибки на основе состояния старшего полубайта BCD
8-битный код на выходе ИС 74LS373 является кодом с фиксацией состояния. Этот код не представляет собой обычный байт (8 двоичных разрядов), но является двумя 4-битными двоично-десятичными кодами (полубайт). В таблице 7.1 приведено соответствие между двоично-десятичным кодом и стандартным двоичным числом.
Как вы можете заметить, до числа 10 двоичный и двоично-десятичный коды совпадают. На числе 10 в двоично-десятичном коде единица «перепрыгивает» в старший полубайт, а младший полубайт обнуляется. В простом двоичном коде подобная операция (перенесение единицы в старший полубайт и обнуление младшего) осуществляется на числе 16. Если вход компьютера настроен на чтение двоичных чисел, то при подаче двоично-десятичного кода возникнут ошибки.
Таблица 7.1

Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
СТАНДАРТЫ НА РЕШЕНИЕ ИЗОБРЕТАТЕЛЬСКИХ ЗАДАЧ
СТАНДАРТЫ НА РЕШЕНИЕ ИЗОБРЕТАТЕЛЬСКИХ ЗАДАЧ В предыдущей главе мы начали построение многоэтажной пирамиды приемов: простые приемы, парные приемы, комплексы приемов... Усложняется структура, увеличивается сила приемов, начинает проявляться их специализация,
9.9. Решение уравнений
9.9. Решение уравнений С развитием техники счета и вообще с развитием цивилизации стали появляться и решаться все более сложные уравнения. Древние не знали, конечно, современного алгебраического языка, они выражали уравнения на обычном разговорном языке подобно тому, как
6.8.2 Решение проблемы
6.8.2 Решение проблемы Данная работа состоит из следующей задачи:6.8.2.1 При выявлении проблем (включая обнаруженные несоответствия) в программном продукте или работе должен быть подготовлен отчет по проблеме, описывающий каждую выявленную проблему. Отчет по проблеме должен
Глава 14 Решение нетривиальных изобретательских задач
Глава 14 Решение нетривиальных изобретательских задач Studendum in impossibile. Учиться на невозможном. Основная цель этой главы – показать изобретателям: широту и: разнообразие возможных объектов изобретений, хоть и спорных с точки зрения патентного законодательства, но тем
Решение логических задач
Решение логических задач Важнейшим практическим результатом кибернетики является использование знаний о работе нервной системы животных и человека для конструирования машин, способных выполнять некоторые их функции. Рис. 68. Логические элементы И, ИЛИ, НЕСовременная
Решение о пилотируемом полете на Луну
Решение о пилотируемом полете на Луну Теперь их стало два. Первый и самый главный — восстановить подорванные престиж и самоуважение Америки. Подобная задача могла быть решена только успешным осуществлением какого-либо проекта, который затмил бы советские космические
Ловин Джон
Просмотр ограничен
Смотрите доступные для ознакомления главы 👉