Криптоанализ зашифрованного текста

Предположим, что мы перехватили это зашифрованное сообщение. Задача состоит в том, чтобы дешифровать его. Мы знаем, что текст написан на английском языке и что он зашифрован с помощью одноалфавитного шифра замены, но мы ничего не знаем о ключе. Поиск всех возможных ключей практически невыполним, поэтому нам следует применить частотный анализ. Далее мы шаг за шагом будем выполнять криптоанализ зашифрованного текста, но если вы чувствуете уверенность в своих силах, то можете попытаться провести криптоанализ самостоятельно.
При виде такого зашифрованного текста любой криптоаналитик немедленно приступит к анализу частоты появления всех букв; его результат приведен в таблице 2. Нет ничего удивительного в том, что частотность букв различна. Вопрос заключается в том, можем ли мы на основе частотности букв установить, какой букве алфавита соответствует каждая из букв зашифрованного текста. Зашифрованный текст сравнительно короткий, поэтому мы не можем непосредственно применять частотный анализ. Было бы наивным предполагать, что наиболее часто встречающаяся в зашифрованном тексте буква O является и наиболее часто встречающейся буквой в английском языке — e или что восьмая по частоте появления в зашифрованном тексте буква Y соответствует восьмой по частоте появления в английском языке букве h. Бездумное применение частотного анализа приведет к появлению тарабарщины. Например, первое слово РС<2 будет расшифровано как аоv.
Таблица 2 Частотный анализ зашифрованного сообщения.
Начнем, однако, с того, что обратим внимание только на три буквы, которые в зашифрованном тексте появляются более тридцати раз: O, X и P. Естественно предположить, что эти наиболее часто встречающиеся в зашифрованном тексте буквы представляют собой, по всей видимости, наиболее часто встречающиеся буквы английского алфавита, но не обязательно в том же порядке. Другими словами, мы не можем быть уверены, что O = e, X = t и P = а, но мы можем сделать гипотетическое допущение, что:
O = e, t или а, X = e, t или а, P = e, t или а.
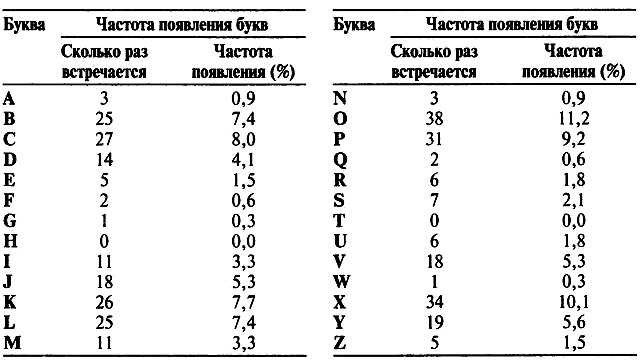
Чтобы быть уверенным в своих дальнейших действиях и идентифицировать три чаще всего встречающихся буквы: O, X и P, нам потребуется применить частотный анализ более тонким образом. Вместо простого подсчета частоты появления трех букв, мы можем проанализировать, как часто они появляются рядом с другими буквами. Например, появляется ли буква O перед или после некоторых других букв, или же она стремится стоять рядом только с некоторыми определенными буквами? Ответ на этот вопрос будет убедительно свидетельствовать, является ли буква O гласной или согласной. Если O является гласной, то она должна появляться перед и после большинства других букв, если же она представляет собой согласную, то она будет стремиться избегать соседства со множеством букв. Например, буква e может появиться перед и после практически любой другой буквы, в то время как буква t перед или после букв b, d, g, j, k, m, q и v встречается редко.
В нижеприведенной таблице показано, насколько часто каждая из трех чаще всего встречающихся в зашифрованном тексте букв: O, X и P появляется перед или после каждой буквы. O, к примеру, появляется перед А в 1 случае, но никогда сразу после нее, поэтому в первой ячейке стоит 1. Буква O соседствует с большинством букв, и существует всего 7 букв, которых она совершенно избегает, что показано семью нулями в ряду O. Буква X общительна в не меньшей степени, так как она тоже стоит рядом с большинством букв и чурается только 8 из них. Однако буква P гораздо менее дружелюбна. Она приветлива только к нескольким буквам и сторонится 15 из них. Это свидетельствует о том, что O и X являются гласными, а P представляет собой согласную.

Теперь зададимся вопросом, каким гласным соответствуют O и X. Скорее всего, что они представляют собой e и а — две наиболее часто встречающиеся гласные в английском языке, но будет ли O = e и X = а, или же O = а, а X = e? Интересной особенностью в зашифрованном тексте является то, что сочетание ОО появляется дважды, а XX не попадается ни разу. Так как в открытом английском тексте сочетание букв ее встречается значительно чаще, чем аа, то, по всей видимости, O = e и X = а.
На данный момент мы с уверенностью определили две буквы в зашифрованном тексте. Наш вывод, что X = а, основан на том, что в зашифрованном тексте в некоторых позициях X стоит отдельным словом, а а — это одно из всего двух слов в английском языке, состоящих из одной буквы. В зашифрованном тексте есть еще одна отдельно стоящая буква, Y, и это означает, что она представляет собой второе однобуквенное английское слово — і. Поиск однобуквенных слов является стандартным криптоаналитическим приемом, и я включил его в список советов по криптоанализу в Приложении В. Этот прием срабатывает только потому, что в данном зашифрованном тексте между словами остались пробелы. Но зачастую криптографы удаляют все пробелы, чтобы затруднить противнику дешифрование сообщения.
Хотя у нас есть пробелы между словами, однако следующий прием сработает и там, где зашифрованный текст был преобразован в непрерывную строку символов. Данный прием позволит нам определить букву h после того, как мы нашли букву e. В английском языке буква h часто стоит перед буквой e (как, например, в the, then, they и т. п.), но очень редко после e. В нижеприведенной таблице показана частота появления буквы O, которая, как мы полагаем, является буквой e, перед и после всех других букв в зашифрованном тексте. На основе этой таблицы можно предположить, что В представляет собой букву h, потому что она появляется перед O в 9 случаях, но никогда не стоит после нее. Никакая другая буква в таблице не имеет такой асимметричной связи с O.
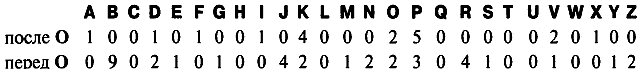
Каждая буква в английском языке характеризуется своими собственными, присущими только ей индивидуальными особенностями, среди которых частота ее появления и ее связь с другими буквами.
Именно эти индивидуальные особенности позволяют нам установить истинное значение буквы, даже когда она была скрыта с использованием шифра одноалфавитной замены.
Теперь мы уже гарантированно определили значение четырех букв: O = e, X = a, Y = i и B = h и можем приступить к замене отдельных букв в зашифрованном тексте их эквивалентами для открытого текста. При замене я буду придерживаться следующего правила: буквы зашифрованного текста останутся прописными, а подставляемые буквы для открытого текста будут строчными. Это поможет нам отличить те буквы, которые нам еще только предстоит определить, от тех, значение которых мы уже установили.

Этот несложный шаг даст нам возможность определить еще несколько букв, поскольку сейчас мы можем отгадать отдельные слова в зашифрованном тексте. К примеру, самыми часто встречающимися трехбуквенными словами в английском языке являются the и and, и их сравнительно легко найти в тексте: Lhe, которое появляется шесть раз, и aPV, которое появляется пять раз. Следовательно, L, по всей видимости, является буквой t, P — n, а V — d. Теперь мы можем заменить и эти буквы в зашифрованном тексте, подставив вместо них их действительные значения:

Как только будут определены несколько букв, дальнейший процесс дешифрования пойдет очень быстро. Так, в начале второго предложения стоит слово Cn. В каждом слове есть гласная, поэтому C должна быть гласной. Нам осталось определить только две гласные: u и o; u не подходит, значит, C должна быть буквой o. У нас также есть слово Khe, в котором К может быть либо t, либо s. Но мы уже знаем, что L = t, поэтому совершенно очевидно, что К = s. Установив значения этих двух букв, подставим их в зашифрованный текст, в результате чего получим фразу thoMsand and one niDhts. Здравый смысл подсказывает, что это должно быть thousand and one nights, и, скорее всего, данный отрывок взят из «Тысячи и одной ночи». Отсюда получаем, что M = u, I = f, J = r, D = g, R = I и S = m.
Мы можем постараться определить другие буквы, подбирая другие слова, но давайте вместо этого посмотрим, что нам известно об алфавите открытого текста и о шифралфавите. Эти два алфавита образуют ключ и применяются криптографом для выполнения замены, благодаря которой сообщение становится зашифрованным. Ранее, определив истинные значения букв в зашифрованном тексте, мы успешно подобрали элементы шифралфавита. То, чего мы достигли на данный момент, представлено ниже, в алфавите открытого текста и шифралфавите.
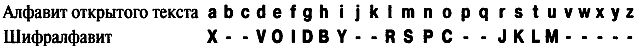
Анализируя частично заполненную строку шифралфавита, мы можем завершить криптоанализ. Последовательность VOIDBY в шифралфавите дает возможность предположить, что в качестве ключа криптограф использовал ключевую фразу. Можно догадаться, что ключевой фразой здесь будет A VOID BY GEORGES PEREC, которая, после того как будут убраны пробелы и повторы букв, сократится до AVOIDBYGERSPC. После нее буквы следуют в алфавитном порядке, при этом те из них, которые уже встречались в ключевой фразе, пропускаются. В данном частном случае криптограф расположил ключевую фразу не в начале шифралфавита, а начиная с третьей буквы. Это допустимо, поскольку ключевая фраза начинается с буквы A, криптограф же хочет избежать зашифровывания a как A. Наконец, определив шифралфавит, мы можем полностью дешифровать весь зашифрованный текст, и криптоанализ будет закончен.
[7]
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК