Сигналы магистрали и ее функционирование
Типовая магистраль данных микроЭВМ имеет около 50-100 сигнальных линий, предназначенных для передачи данных, адресов и управляющих сигналов. IBM PC/XT — типичный микрокомпьютер, внутренняя магистраль которого состоит из 53 сигнальных линий и 8 линий, предназначенных для подачи питания и заземления. Для того чтобы не обрушивать на вас все эти сигналы сразу, мы будем приближаться к осмыслению полного набора сигналов, «надстраивая» магистраль, начав с такого количества сигнальных линий, какое необходимо для простейшего режима обмена данными (программируемого ввода-вывода) и добавляя по мере необходимости дополнительные сигнальные линии. Далее мы приведем несколько полезных примеров организации сопряжения тех или иных узлов с магистралью для того, чтобы всесторонне обсудить эту тему, не теряя интереса читателя.
10.05. Основные сигналы магистрали: данные, адрес, синхронизация
Для того чтобы переслать данные на магистраль с разделяемыми ресурсами (мультиплексируемую), вы должны уметь описать сами данные, приемник, а также момент, когда данные являются достоверными. Таким образом, по минимуму магистраль должна иметь шину данных (для передачи данных), адресную шину (для того чтобы идентифицировать устройство ввод-вывода или адрес в памяти) и несколько линий синхронизации, или стробирования (которые сообщают, когда передаются данные). Обычно в шине данных предусматривается столько же проводников, сколько разрядов в компьютерном слове, чтобы можно было сразу передать все слово. Однако в PC есть только 8 проводников шины данных (D0-D7); за один цикл передачи вы можете переслать байт, но для того, чтобы переслать 16-разрядное слово, необходимо выполнить два цикла передачи. Количество разрядов шины адреса определяет количество адресуемых устройств: если магистраль используется для обращения как к устройствам ввода-вывода, так и к памяти (стандартная ситуация), она должна иметь от 16 до 32 проводников адресной шины, что соответствует адресному пространству от 64 Кбайт до 4 Гбайт; магистраль, используемая только для ввода-вывода, может иметь от 8 до 16 разрядов адреса (от 256 до 64 К устройств ввода-вывода). [IBM PC общается по своей магистрали как с памятью, так и с устройствами ввода-вывода и имеет 20 адресных проводников (А0-А19), что соответствует 1 Мбайт адресного пространства.] И наконец, передаваемые данные синхронизуются стробирующими импульсами, передаваемыми по дополнительным проводникам магистрали. Для того чтобы реализовать описанную схему, существуют два пути: предусмотреть отдельные линии «чтение» и «запись» (с названиями, например, READ и WRITE) и возбуждать на той или другой из этих линий сигналы, синхронизирующие передачу данных; иметь одну линию стробирующих сигналов (STROBE) и одну линию READ/WRITE', причем импульс на линии STROBE синхронизирует передачу данных в направлении, которое определяется уровнем сигнала на линии READ/WRITE'. IBM PC использует схему (действующий уровень сигнала-низкий) с линиями «чтение/запись», названными IOR', IOW', MEMR' и MEMW'. Поскольку PC различает память и устройства ввода-вывода, то и линий этих четыре, по два строба (чтения и записи) на тот и другой тип ввода-вывода.
Сигналы данных, адреса и четыре строб-сигнала — это обычно все, что требуется для организации простейшего режима передачи данных. Однако для PC необходим еще один сигнал, названный выбор адреса (AEN — Adress ENable) для того, чтобы различать обычную передачу данных в устройстве ввода-вывода от режима передачи, называемого прямой доступ к памяти (ПДП) (DMA — Direct Memory Access). Режим ПДП мы рассмотрим в разд. 10.12, а сейчас вам достаточно знать, что AEN имеет низкий уровень для обычного ввода-вывода и высокий-для режима ПДП. Таким образом, сейчас у нас есть 33 сигнала магистрали: D0-D7, А0-А19, IOR', IOW', MEMR', MEMW' и AEN. Давайте посмотрим, как они работают.
10.06. Программируемый вывод данных ввод-вывод:
Простейший метод обмена данными по магистрали компьютера известен как программируемый ввод-вывод, это обозначает, что данные передаются с помощью операторов программы IN или OUT (направления передачи для IN и OUT входят в состав тех немногих правил, которых придерживаются все изготовители компьютеров: IN всегда означает направление к ЦП, a OUT всегда означает направление из ЦП). В целом процесс вывода данных (и записи в ОЗУ) предельно прост и логичен (рис. 10.6).
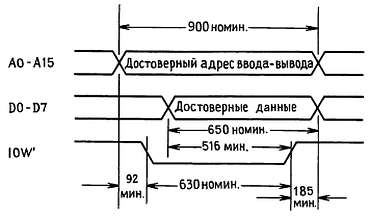
Рис. 10.6. Цикл ввода-вывода при записи (все измерения в нc).
Адрес приемника и данные, которые необходимо передать, выставляются на соответствующие линии магистрали центральным процессором. Строб-сигнал записи (IOW' или MEMW') устанавливается в низкое состояние цетральным процессором для того, чтобы сигнализировать приемнику о том, что данные установлены и их можно считывать. На магистрали PC адрес гарантированно установлен, начиная с момента времени приблизительно за 100 нс до IOW', а данные гарантированно установлены по крайней мере за 500 нс до окончания IOW' (и в течение следующих 185 нс после окончания этого сигнала).
Для того чтобы принимать участие в подобных играх, периферийное устройство (пусть в нашем случае это — графический дисплей) наблюдает за шинами адреса и данных. Когда устройство обнаруживает свой собственный адрес, оно считывает информацию с шины данных по спаду сигнала IOW'. Вот и все.
Рассмотрим пример, приведенный на рис. 10.7.
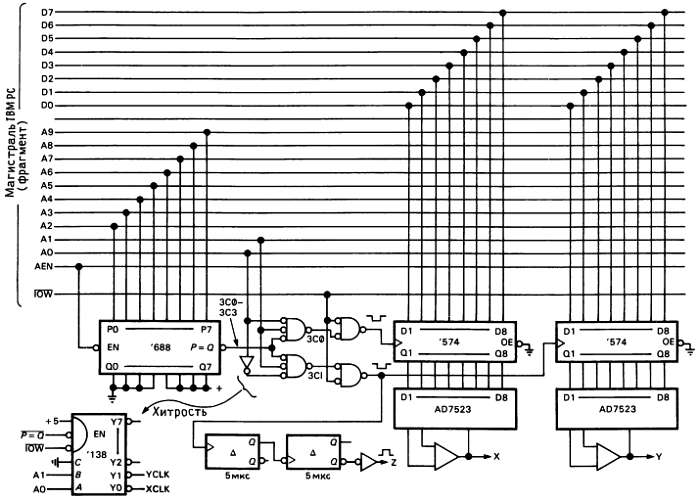
Рис. 10.7. Растровый дисплей.
Здесь мы спроектировали растровый графический дисплей; вы последовательно передаете ему пары чисел X, Υ и на его экране отображается каждая точка в декартовой прямоугольной системе координат, причем первое число соответствует абсциссе, а второе — ординате отображаемой точки. Сначала мы должны выбрать адрес устройства ввода-вывода. На рис. 10.8 приведены зарезервированные и доступные адреса устройства ввода-вывода для IBM PC; мы выбираем 3C0H для Х-регистра и ЗС1Н для Y-peгистра.

Рис. 10.8. Адреса ввода-вывода IBM PC.
Микросхема `688-8-разрядный компаратор со стробированием; состоянию равенства сравниваемых кодов которого соответствует низкий уровень на выходе, вырабатывает низкий выходной сигнал в том случае, когда 8 бит разрядов А2-А9 совпадают с заданными значениями, в нашем случае - когда адрес на магистрали лежит в диапазоне 3C0H-3С3Н (вы можете использовать комбинационную схему, но компаратор адреса компактнее). Мы также потребуем в соответствии с ранее приведенными разъяснениями, чтобы AEN был низкого уровня. Трехвходовые логические схемы И-НЕ завершают дешифрацию адреса, используя адресные линии А0, А1 для того, чтобы установить низкий уровень на своих выходах отдельно для адресов 3C0H и ЗС1Н (другой способ будет вкратце описан ниже). В конце концов указанные выходы логически перемножаются с IOW' для того, чтобы получить синхросигнал для Х- и Y-регистров, которые представляют собой 8-разрядные регистры на D-триггерах (микросхемы `574). Эти регистры фиксируют байты с шины данных в тех случаях, когда а) выбран требуемый адрес, б) сигнал AEN — в низком состоянии, в) был выработан сигнал IOW'. Восьмиразрядные цифро-аналоговые преобразователи (ЦАП) преобразуют считываемые байты в аналоговое напряжение, подаваемое на Х- и Y-входы устройства управления выводом на электронно-лучевую трубку (ЭЛТ) дисплея. Спустя несколько микросекунд после считывания Y-координаты, два одновибратора вырабатывают 5-микросекундный импульс подсветки, увеличивающий интенсивность свечения изображаемой на экране точки (все устройства управления выводом на ЭЛТ имеют для этого вход Z). Для того чтобы изобразить график или набор символов на экране, необходимо последовательно выводить Х- и Y-координаты, повторяя их в одном и том же порядке (сначала X, а затем Y) достаточно быстро, чтобы глаз не видел мерцания.
Микрокомпьютеры достаточно быстры для того, чтобы успевать в цикле отображать на дисплее несколько тысяч точек без раздражающего мерцания. Учитывая, что растровый дисплей — это стандартное устройство микрокомпьютера для вывода изображений, приведенный пример более полезен в качестве модели фотографического графопостроителя сверхвысокого разрешения, использующего 14-разрядный ЦАП и дисплей с микроскопическим размером точек (см. следующее упражнение).
Несколько полезных замечаний:
а) Отметим, что мы подобрали полярность сигналов таким образом, что D-триггеры переключаются по спаду сигналов IOW'; это существенно, так как в момент времени, соответствующий фронту этого импульса, данные могут еще не установиться. Для большей надежности следует удостовериться, что временные соотношения сигналов удовлетворяют временам упреждения и удержания схем `574; фактически, однако, для такой медленной, как у IBM PC магистрали трудно заставить схему, подобную описываемой, работать правильно, поскольку с момента установки данных до спада IOW' проходит более 500 нc.
б) Вы можете сэкономить несколько логических элементов, использовав в цепи дешифрации адреса стробируемый дешифратор так, как показано на рисунке. Дешифраторы типа,138 (3 разряда на 8 направлений) и типа `139 (сдвоенный, 2 разряда на 4 направления) имеют один или более стробирующих входов и удобны для построения схем такого рода.
в) Отметим также, что мы могли бы объединить 3-входовые и 2-входовые элементы И-НЕ в 4-входовые И-НЕ, здесь этого не сделано для того, чтобы четче выделить отдельно факт дешифрации адреса и затем — совпадения результата дешифрации со строб-сигналом IOW'.
г) На самом деле мы можем полностью игнорировать разряд А1 и схема будет работать по-прежнему! Однако тогда она начнет откликаться также на адреса 3С2 и 3С3 (как X и Y, соответственно) и произойдет потеря двух адресов ввода-вывода. На практике, однако, часто идут этим путем и, не полностью дешифруя адрес, экономят микросхемы (ведь адресное пространство остается достаточно обширным, даже если вы и потеряете таким образом некоторое количество адресов). В рассматриваемом примере мы можем подключить IOW' вместо А1 и полностью отказаться от 2-входовой схемы И-НЕ.
д) Сопряжение с магистралью, подобное обсуждаемому, будет более гибким, если адрес устанавливать DIP-переключателями (или DIP-перемычками); тогда вы сможете выбрать адрес верно, чтобы не было конфликта с адресом другого устройства, подключенного к той же магистрали. Внести соответствующие изменения в схему несложно-достаточно восемь входов компаратора подсоединить через ключи к общему проводнику («земле»), а через резисторы — к цепи +5 В.
е) Для пояснения существа дела в этом примере мы использовали отдельные микросхемы 8-разрядных регистров и ЦАПов. На практике у вас есть возможность применить ЦАП со встроенной схемой выборки адреса (например, «микропроцессорно-совместимый» ЦАП типа AD 7528-сдвоенный ЦАП с входной схемой выборки адреса); такая схема выпускается даже в счетверенном варианте (AD7226), а также в варианте с двойной буферизацией, двухкаскадной выборкой адреса для каждого ЦАП (счетверенный ЦАП AD 7225).
Упражнение 10.1. Нарисуйте функциональную схему адресного компаратора с настройкой адреса.
Упражнение 10.2. Нарисуйте схему сопряжения растрового дисплея с магистралью, используя 16-разрядные ЦАП для преобразования как Х-, так и Υ-κοординат. Вам потребуется 4 последовательно расположенные адреса. Используйте первые 2 для регистрации Х-регистра, а два последних-для Y-регистра; конечно, надо предусмотреть возможность настройки базового адреса ввода-вывода с использованием переключателей в DIP-исполнении. Как для Х-, так и для Y-координат четным адресам соответствует младший, а нечетным — старший байт соответствующего кода; это удобно (поскольку МП 8086 оперирует 16-разрядными словами, можно пользоваться командами ввода-вывода слов для передачи данных этому устройству).
Программирование графического дисплея. Программирование такого устройства не представляет сложностей. Как это делается показывает программа 10.3, которой надо указать адреса ячеек, где хранятся Х- и Y-координаты первой точки и количество точек, которое надо отобразить. Программа обслуживания дисплея возможно, будет оформлена как подпрограмма с этими параметрами, передаваемыми при ее вызове. Программа заносит адреса массивов Х- и Y-координат (т. е. адрес первой пары Х-, Y-координат) в индексные регистры SI и DI, а байт количества точек в регистр СХ. Этот регистр потом используется в цикле, в котором пары Х-, Y-координат последовательно передаются в порты ввода-вывода по адресам 3C0 и ЗС1. В каждом цикле перемещаются указатели массивов X и Υ; а содержимое счетчика декрементируется и сравнивается с нулем, который характеризует отображение последней точки; затем указатели и счетчик устанавливаются в исходное состояние и процесс вывода начинается снова.

Пара важных моментов: однажды запустившись, программа постоянно отображает массив точек. В действительности программа должна проверять состояние клавиатуры, чтобы заметить, если оператор захочет прекратить вывод на дисплей. Можно также прекратить вывод спустя заданное время или с помощью прерывания, о чем речь будет идти ниже.
Обычно при регенерации изображения на дисплее, организованной подобным образом, для дополнительных продолжительных вычислений во время вывода изображения времени нет. Гораздо лучшим методом является обновление изображения на экране из собственной памяти дисплея, что разгружает компьютер. Как бы то ни было, если ваша цель — построить изображение с высоким разрешением для получения фотографической копии, эта программа и схема сопряжения, спроектированная по условиям упражнения 10.2, будет работать замечательно.
10.07. Программируемый ввод-вывод: ввод данных
Передача данных в другом направлении при программируемом вводе-выводе осуществляется столь же просто. Схема сопряжения следит за шиной адреса так же, как и ранее. Если эта схема обнаруживает свой собственный адрес (и сигнал AEN находится в низком состоянии), она выставляет данные на шину данных, обеспечивая их совпадение во времени с сигналом IOR' (рис. 10.9).
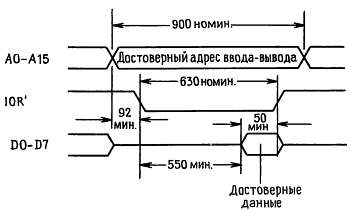
Рис. 10.9. Цикл ввода-вывода при чтении.
Пример такой схемы приведен на рис. 10.10.
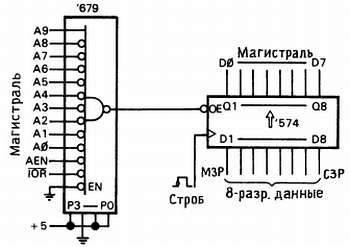
Рис. 10.10. Параллельный входной порт.
Схема позволяет компьютеру считать байт, хранящийся в регистре на D-триггерах типа `574. Поскольку и тактовый вход, и входы данных регистра доступны внешнему устройству, в регистр может быть занесена цифровая информация практически любого характера (выход цифрового прибора, АЦП и т. п.). Для разнообразия мы использовали вместо всех логических элементов 2-разрядный дешифратор адреса типа `679. Эта «умная микросхема» имеет 12 адресных входов, вход выборки и 4 «программируемых» входа. Если вы хотите дешифровать некоторый определенный адрес, это делается хитро: функционально такая микросхема представляет собой 12-входовую схему И-НЕ, программируемое число этих входов может быть дополнительно инвертировано; инвертируются всегда входы с меньшими номерами, а их количество вы можете задавать с помощью 4-х отдельных программируемых входов.
Пусть мы хотим «добраться» до резервного порта ввода-вывода с адресом 200Н (рис. 10.8). Нам необходимо распознать состояние А9 — высокий уровень, А0-А8 — низкий. Ко всему прочему мы можем использовать микросхему `679 для стробирования дешифрованного адреса низкими уровнями сигналов AEN и IOR'.
Итак, окончательно нам требуется схема И-НЕ с 11-ю инвертирующими входами и одним неинвертирующим входом, что обеспечивается подачей кода 1011, осуществляемой аппаратным образом на программируемые входы. Затем подключим адресную шину и синхросигналы так, как показано на рис. 10.10. Как только команда
IN AL,200H
выполнится, ЦП выставляет адрес 200Н на линиях А0-А9 и затем устанавливает IOR' на время 630 нc. Центральный процессор считывает то, что он обнаруживает на шине данных (D0-D7) в момент времени, соответствующий спаду сигнала IOR', затем сбрасывает А0-А9.
Реакция периферийного устройства должна заключаться в том, чтобы выдать данные на соответствующие разряды D0-D7 по крайней мере за 50 нc до конца IOR'; выполнить это условие не составляет никакого труда, так как устройству известно, что от него требуются данные, уже по меньшей мере 600 не. Для типовой задержки срабатывания используемых здесь микросхем 10 нc, 600 нс выглядят вечностью.
Начиная с этого примера, мы прекратим пристально рассматривать весь клубок линий магистрали, а просто будем называть отдельные линии по именам.
Сигналы магистрали: двунаправленность и однонаправленность. Из двух примеров, которые мы рассмотрели до сих пор, вы могли увидеть, что некоторые линии магистрали являются двунаправленными, например линии шины данных: во время записи на них выставляется выходной код ЦП, а во время чтения — выходной код периферийного устройства. Как ЦП, так и периферийное устройство для подключения к таким линиям используют элементы с третьим состоянием на выходе.
Другие сигналы, такие как IOW' и IOR', всегда вырабатываются ЦП с помощью стандартных драйверов. Типичным для компьютерных магистралей является существование обоих типов линий, двунаправленных линий для данных, передаваемых как в одном, так и в другом направлении, и однонаправленных линий для сигналов, которые всегда вырабатываются ЦП (или, более точно, соответствующими логическими схемами управления магистралью). Процессор всегда использует какой-то простой протокол, вроде наших правил установки/чтения в соответствии с сигналами IOW', IOR' и адресными, который предотвращает конфликтные ситуации на совместно используемых линиях магистрали.
Среди перечисленных до сих пор только шина данных является двунаправленной; адрес, сигнал AEN и синхросигналы распространяются только в одном направлении — от ЦП. (Чтобы не создавать неправильного впечатления, надо уточнить, что более сложные компьютерные системы позволяют другим адресатам магистрали становиться ее «хозяевами»; очевидно, в таких системах почти все сигналы магистрали являются мультиплексируемыми и двунаправленными. IBM PC в этом отношении необычайно проста.)
10.08. Программируемый ввод-вывод: регистры состояний
В нашем последнем примере компьютер мог считать байт из схемы сопряжения в любое время, когда захочет. Это замечательно, но как узнать, когда можно считать что-нибудь стоящее? В некоторых случаях вы можете потребовать, чтобы компьютер считывал данные через равные интервалы времени, отсчитываемые его таймером реального времени. Пусть например, компьютер «заставляет» АЦП начинать преобразование через равные промежутки времени (командой OUT) и затем считывает результат несколькими микросекундами позже (командой IN). В измерительных системах этого может быть вполне достаточно. Однако часто встречаются такие случаи, когда внешнее устройство имеет свой собственный «интеллект», и было бы хорошо, если бы оно могло без промедления сообщить компьютеру, что что-то произошло.
Классическим примером является алфавитно-цифровой ввод при нажатии каких-либо клавиш клавиатуры дисплея. Если вы не хотите терять символы, компьютер должен ввести каждый из них и без большой задержки. Еще более серьезная ситуация с быстрым накопительным устройством, таким как диск или ленточный магнитофон; данные необходимо передавать со скоростью до 100000 байт в секунду без задержки. Для того чтобы решить эту проблему, существуют три реальные возможности: использовать регистры состояний, прерывания и прямой доступ в память (ПДП). Давайте начнем с простейшего метода-регистров состояния — проиллюстрированного схемой сопряжения клавиатуры на рис. 10.11.
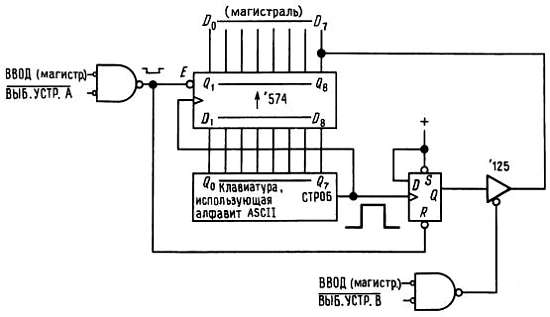
Рис. 10.11. Интерфейс клавиатуры с битом состояния.
В этом примере ASCII-код записывается в 8-разрядный регистр на D-триггерах типа `574 строб-сигналом, вырабатываемым клавиатурой при нажатии на очередную клавишу. Мы соорудили типовое программируемое устройство ввода данных так, как показано на рис. 10.11, используя трехстабильные выходы микросхемы `574 для непосредственной связи с шиной данных. Входной сигнал, обозначенный как KBDATA SEL', поступает от схемы дешифратора адреса того же в точности типа, который приведен в предыдущем примере, и устанавливается в низкое состояние, когда код адреса, предварительно присвоенного данному устройству, появляется на шинах адреса магистрали (вместе с низким уровнем сигнала AEN).
Что в этом примере нового, так это — триггер, который устанавливается в единичное состояние, когда клавиша некоторого символа нажата и сбрасывается, когда символ считывается компьютером. Фактически это — одноразрядный регистр состояния, высокий уровень выходного сигнала которого означает возможность считать очередной символ, низкий уровень — отсутствие таковой. Компьютер может опросить бит состояния, выполнив команду ввода данных IN с другого адреса рассматриваемого устройства, дешифрованного как KBFLAG SEL' (с помощью логических вентилей, дешифраторов или каких-либо других элементов).
Для того чтобы описать состояние этого устройства, требуется только один бит, поэтому схема сопряжения управлялась только битом старшего разряда, в данном случае с помощью буфера с тремя выходными состояниями типа `125. (Никогда не подключайте двунаправленные линии к выходам устройств, специально для этого не предназначенным!) Линия, подходящая на рисунке к изображению буфера снизу, управляет трехстабильным выходным сигналом, разрешая его своим низким уровнем, что обозначено кружком.
Клавиатура терминала: пример программы. Итак, теперь у компьютера имеется возможность узнать, когда готовы очередные данные. Программа 10.4 показывает как.

Эта программа предназначена для того, чтобы считывать символы с клавиатуры терминала, адрес порта данных которого — KBDATA (хорошим стилем программирования является определение действительного кода адреса порта, который соответствует адресу, определяемому аппаратным образом, как KBDATA SEL и т. п. — несколькими операторами, располагаемыми в начале программы, как показано); каждый символ отображается (режим «эхо») на экране дисплея компьютера (адрес порта = OUTBYTE). Когда набирается целая строка, программа передает управление блоку обработки строки, функционирование которого определяется символьным содержанием строки. Когда программа готова к обработке другой строки, она печатает звездочку. Если у вас есть какой-то опыт в работе на компьютере, программа покажется вам достаточно очевидной.
Программа начинается с инициализации указателя буфера символов, осуществляемой пересылкой адреса буфера в адресный регистр ВР. Отметим, что мы не можем записать
MOV BP,charbuf
так как такая команда загрузит содержимое, а не адрес; в языке ассемблера процессора 8086 для обозначения адреса ячейки памяти используют слово offset перед идентификатором этой ячейки. После этого программа с помощью команды IN считывает бит состояния клавиатуры, логически умножает его на 80Н, чтобы оставить только бит состояния (это называется «маскированием») и результат сравнивает с нулем. Нуль означает, что бит не равен единице и программа выполняет цикл. Когда обнаружен ненулевой бит состояния, программа считывает данные из порта данных клавиатуры (при этом обнуляется бит состояния триггера) и последовательно запоминает их в буфере строки, инкрементируя указатель (ВР) и вызывая подпрограмму, которая отображает символ на экран. Наконец, программа проверяет, не оканчивается ли строка символом возврата каретки: если этого нет, то управление передается циклу повторной проверки бита состояния клавиатуры; если последний символ является символом перевода строки (CR), программа передает управление обработчику строки, после чего печатает звездочку и начинает все заново.
Даже простая подпрограмма, используемая для вывода символа на дисплей, требует нескольких операций проверки флага (бита) состояния и маскирования. Сначала подпрограмма запоминает байт в регистре АН, затем считывает и маскирует флаг занятости экрана дисплея. Ненулевой флаг означает, что дисплей занят и надо продолжить проверку этого флага; в противном случае подпрограмма заносит символ в регистр AL, пересылает этот символ в порт данных дисплея и завершается.
Несколько замечаний по программе: а) поскольку бит старшего разряда (который мы аппаратным образом определили как бит флага) является знаковым, стадию маскирования флага клавиатуры можно опустить; при этом можно использовать команду JPL KFCHK. Эта уловка, однако, срабатывает только при проверке старшего разряда и поэтому весьма специфична; б) продолжая практику хорошего стиля программирования, символ возврата каретки (0DH) и звездочки можно было бы определить как константы, подобно KBMASK; в) блок обработки строки может быть оформлен в качестве подпрограммы; г) в том случае, если процедура обработки строки слишком длинна, могут быть потеряны символы; это соображение приводит к использованию более изящного механизма прерывания, который мы вскоре рассмотрим; д) программы обслуживания клавиатуры и дисплея используются настолько часто, что PC имеет встроенные программы такого рода, вызываемые посредством программных прерываний (рассмотрим их позже); таким образом, наша программа вообще не нужна!
Обобщение битов состояний. Пример с клавиатурой иллюстрирует протокол обработки бита состояния; однако протокол настолько прост, что у вас может создаться неправильное представление об этом предмете. На самом деле интерфейс внешнего устройства несколько сложнее, как правило он предусматривает несколько флагов для фиксации различных условий. Например, в интерфейсе ленточного магнитофона вам, как правило, надо иметь следующие биты состояний: начало ленты, конец катушки, ошибка четности, движение ленты и т. д. Традиционная процедура заключается в том, чтобы свести все биты состояний в один байт или слово так, чтобы сразу считать все биты из регистра состояний с помощью команды ввода данных IN. Обычно надо назначить бит, показывающий наличие любой из ошибочных ситуаций, старшему разряду слова состояний с тем, чтобы простая проверка знака сигнализировала бы о наличии какой-нибудь ошибки; если это обнаруживается, можно проверять отдельные разряды слова (накладывая маску с помощью логической функции «И») для выявления конкретной ошибки. Более того, в сложных интерфейсах, возможно, не требуется, чтобы биты состояния сбрасывались «автоматически», как это происходило с единственным битом в нашем примере; вместо этого можно воспользоваться командой вывода данных, каждый бит которых сбрасывает соответствующий флаг.
Упражнение 10.3. У нашего интерфейса клавиатуры нет средства, позволяющего компьютеру определить, был ли пропущен символ. Измените схему так, чтобы она использовала два бита состояний: «готовность символа» (это у нас уже есть) и «потеря данных». Флаг «потеря данных» должен устанавливаться на линии D6 того же порта состояний, что и «готовность символа»; флаг «потеря данных» должен становиться равным единице, если клавиша была нажата до того, как предыдущий символ был считан компьютером, в остальных случаях он должен быть равен нулю.
Упражнение 10.4. Дополните программу 10.4 блоком проверки потерянных данных. Это должно осуществляться вызовом подпрограммы с именем LOST в тех случаях, когда флаг «потеря данных» установлен равным единице; в остальных случаях программа должна работать как и раньше.
10.09. Прерывания
Только что проиллюстрированное использование флагов состояний является одним из трех способов, используемых внешним устройством для того, чтобы «намекнуть» компьютеру на необходимость выполнения каких-то действий. Хотя во многих простых случаях этого вполне достаточно, имеется серьезный недостаток в том, что внешнее устройство не может само объявить о необходимости выполнения каких-то действий — оно должно ждать до тех пор, пока ЦП не опросит его посредством считывания содержимого регистра состояния командой IN. Устройствам, которым требуется быстродействие (такие, как диски или другие, чья работа предусматривает ввод-вывод в реальном масштабе времени), необходим частый опрос флагов состояний, и в компьютерной системе с несколькими подобными устройствами ЦП вскоре обнаружит себя проводящим основное время за проверкой флагов состояний, как в последнем примере.
Более того, даже при постоянно выполняемой проверке флагов состояний у вас еще остается повод для беспокойства. В частности, в последнем примере ЦП будет успевать вводить символы, набираемые на клавиатуре, если он находится в главном цикле проверки флагов. Но что, если ЦП затратит 1/10 секунды в той части алгоритма, которая обеспечивает обработку строки? Или дисплей медленный и заставляет программу ждать, пока сбросится флаг занятости? Все, что в таких случаях необходимо, это — механизм, позволяющий внешнему устройству прервать обычный порядок работы ЦП в тех случаях, когда надо что-нибудь сделать. Затем ЦП может проверить регистр состояния для того, чтобы определить, чем вызвано беспокойство, аккуратно сделать то, что положено и вернуться к нормальной работе.
Для того чтобы дополнительно использовать потенциальные возможности прерываний в компьютере, необходимо добавить несколько новых сигналов на магистрали: по крайней мере, одна обобщенная линия для передачи прерываний от внешних устройств и (обычно) пара линий, с помощью которых ЦП может определить, какое устройство выдало сигнал прерывания. К сожалению, пример с IBM PC не очень удачен, так как эта машина не использует всех возможностей прерываний. Однако недостаток гибкости более чем компенсируется простотой; реализация аппаратных прерываний в периферийных устройствах PC проще пареной репы.
Теперь о том, как это все работает: магистраль PC имеет набор из 6-ти линий для передачи сигналов запросов прерываний, именуемых IRQ2-IRQ7. Эти линии используют положительную логику и подключены к схемам обрамления ЦП (в частности, к контроллеру прерываний типа 8259). Для того чтобы возбудить прерывание, вы просто устанавливаете на одной из линий высокий уровень сигнала. Если прерывания разрешены (в том числе и то конкретное IRQ, которое вы выбрали), ЦП после завершения очередной команды прерывает выполнение программы, а затем (после сохранения в стеке флагов и текущего указателя команд) переходит к программе обработчика прерывании, расположенной где-то в памяти.
В обработчике вы предусматриваете любые требуемые действия (например, чтение данных с клавиатуры), и поместить его вы можете где угодно по своему усмотрению; ЦП выясняет, по какому адресу надо совершить переход, анализируя 4-байтовый адрес обработчика, расположенный в выделенной области в начале памяти. Адрес этой области зависит от выбранного IRQ; для МП 8086 16-ричное значение этого адреса вычисляется по формуле 20 + 4n, где n-уровень прерывания. Например, ЦП будет реагировать на прерывание IRQ2 посредством перехода по 4-байтовому адресу, который хранится в ячейках памяти с адреса 28Н по 2ВН (это похоже на косвенную адресацию, с той лишь разницей, что адрес располагается в памяти, а не в регистре); конечно, начальные адреса ваших обработчиков прерываний следует заранее поместить в память. В конце обработчика надо выполнить команду IRET, которая обеспечит восстановление предварительно сохраненного содержимого регистра флагов и передачу управления обратно в точку вызова.
Проиллюстрируем это, добавив в схему интерфейса клавиатуры прерывания (рис. 10.12).
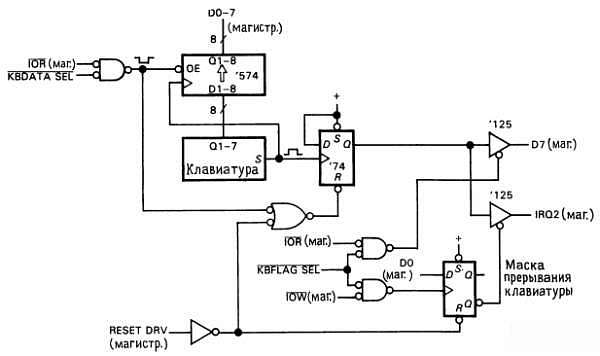
Рис. 10.12. Интерфейс клавиатуры с прерываниями.
Мы оставили флаг «символ готов» и схему программируемого ввода-вывода практически без изменений, за исключением того, что сигнал сброса флага включен по схеме «ИЛИ» с новым сигналом магистрали RESET DRV, который является выходным для ЦП, он на короткое время устанавливается в высокое состояние при включении компьютера. Обычно этот сигнал используется для установки триггеров и других элементов последовательной логики в определенное состояние при включении питания. Очевидно, этот сигнал должен сбросить флаг готовности байта к приему его в программу (в нашем новом интерфейсе установленный флаг готовности даже вызвал бы прерывание). Еще одно внесенное нами изменение — использование сокращенных обозначений для описания разрядности шины данных для того, чтобы сделать схему более удобочитаемой.
Новая схема обработки прерываний включает драйвер для установки IRQ2 в случае готовности символа. Вот и все схемные новшества, которые вам необходимы. Мы добавили, хотя в этом нет обязательной необходимости, возможность отключения устройства выработки сигнала прерывания (которое представляет собой трехстабильный буферный элемент) путем передачи байта, младший разряд которого установлен в низкое состояние, по адресу порта KBFLAG. Это можно будет использовать в том случае, если вам захочется подключить к тому же уровню IRQ другое устройство, вырабатывающее прерывания, причем так, чтобы в каждый момент только одно устройство могло инициировать прерывание (ниже мы дополнительно поясним этот щекотливый момент).
10.10. Обработка прерываний
Компьютеры семейства IBM PC/XT реализуют обработку прерываний просто (хотя и ограничивая при этом гибкость), используя интегральную микросхему контроллера прерываний типа 8259, установленную на базовой плате. Эта микросхема выполняет основной объем работы, которая включает в себя определение приоритетов, маскирование и выбор векторов прерываний (мы опишем это после примера, приведенного ниже). Со своей стороны ЦП определяет, что наступило прерывание и реагирует на это сохранением указателя команд и регистра флагов, а также запрещением дальнейших прерываний, а затем-совершая переход по соответствующему адресу, записанному в области векторов прерываний в начальных ячейках памяти. Ваша программа обработки прерываний делает остальное, а именно: а) сохраняет с помощью команды push все регистры, которые вы собираетесь использовать (напомним, что прерываемая программа не может заранее подготовиться к прерыванию, поскольку оно может произойти в любой момент во время выполнения программы как гром среди ясного неба); б) выясняет, при необходимости, с помощью чтения одного или нескольких регистров состояний, что именно требуется выполнить; в) выполняет это; г) восстанавливает ранее сохраненные регистры из стека; д) сообщает микросхеме 8259, что все сделано (передавая байт признака завершения прерывания 20Н и, наконец, е) выполняет возврат из прерывания — команду IRET, что заставляет ЦП восстановить содержимое прежнего регистра флагов, сохраненное предварительно в стеке и передать управление (использовав прежнее, также предварительно сохраненное в стеке значение указателя команд) обратно в ту программу, выполнение которой было прервано. Где-то в программе вы должны ж) загрузить адрес программы-обработчика прерываний по адресу вектора прерываний, соответствующего уровню IRQ, используемого аппаратной частью компьютера, и сообщить контроллеру прерываний 8259 о том, что необходимо разрешить прерывание указанного уровня.
Программа 10.5 демонстрирует программирование клавиатуры с использованием прерываний. Вот общая схема: главная процедура выполняет необходимые предустановки, а затем в цикле прерывает значение флага (программного, не аппаратного), который устанавливает обработчик прерываний, обнаружив код «возврата каретки»; когда главная процедура замечает, что флаг установлен, она переходит к заданным действиям над строкой, а затем происходит возврат к циклу проверки флага. Обработчик прерываний, в который передается управление при каждом прерывании, заносит символ в буфер строки, устанавливает флаг, если символ оказался «возвратом каретки» и возвращает управление.

Давайте более пристально посмотрим на программу. После задания адреса порта и адреса вектора прерываний IRQ2 она выделяет 100 байт под буфер строки (первоначально буфер заполняется нулями). Собственно выполнение программы начинается с занесения адреса буфера в адресный[6] регистр SI, обнуление флага конца строки, и помещения адреса обработчика прерываний (который начинается с ΚΒΙΝΤ) в ячейку 28Н. Для того чтобы разрешить контроллеру прерываний 8259 прерывания 2-го уровня, обнулим бит 2 маски (команды IN, AND, OUT); затем разрешим прерывания ЦП и передадим единицу в KBFLAG, что приводит к разрешению трехстабильного драйвера.
Теперь можно работать. После этого программа выполняет цикл, а прямо под «носом» главной процедуры скрыто обрабатывается прерывание до тех пор, пока не будет обнаружено, что "buflg" загадочным образом установился. Флаг и указатель буфера немедленно устанавливаются в исходное состояние (на тот случай, если придет следующее прерывание), затем строка «проглатывается». Хорошим советом было бы пожелать либо быстрее выполнять программу, либо скопировать строку в другой буфер, поскольку через несколько миллисекунд может произойти другое прерывание (сопровождаемое занесением нового байта в буфер), однако за это время можно выполнить несколько тысяч команд, что более чем достаточно для копирования строки.
Обработчик прерываний является отдельной программой, которая не входит в главную процедуру. Он активизируется с помощью прерывания 2-го уровня через свой адрес, который, в свою очередь, заранее был загружен по адресу 28Н. Обработчик в точности знает, что должно быть сделано, и делает это безропотно: он сохраняет содержимое регистра АХ (поскольку планирует разнести последнее вдребезги), считывает символ из порта данных клавиатуры, заносит этот символ в буфер, инкрементирует указатель, дополнительно отображает символ на экран (в эхо-режиме), устанавливает флажок (если был введен символ возврата каретки), посылает сигнал об окончании прерывания контроллеру 8259, восстанавливает содержимое регистра АХ и возвращает управление.
Если вы еще раз взглянете на приведенный выше перечень действий, выполняемых обработчиком, то можно заметить, что мы не упомянули только один этап, а именно, считывание флажков состояний, которые позволяют выяснить, какие из нескольких действий должны быть выполнены. В данном случае, поскольку существует единственная причина, вызывающая прерывание, а именно, запрос на ввод очередного символа с клавиатуры, чтение флажков не требуется. (Программист должен отчетливо понимать, при каких условиях происходит аппаратное прерывание и что требуется для его обработки.)
Несколько замечаний по поводу этой программы: во-первых, даже хотя мы и использовали прерывания, программа выглядит столь же тупой, что и раньше — она постоянно выполняет цикл, проверяя состояние признака конца строки. Однако при необходимости можно организовать цикл и по-другому, если необходимо выполнять еще какие-то действия. Это и происходит на самом деле в нашей программе, в той ее части, которая начинается с метки LINE и выполняет вывод символа «звездочка»; в течение этого времени прерывания обеспечивают занесение новых символов в буфер, в то время как в нашем предыдущем примере без прерываний эти символы были бы потеряны.
Второе замечание можно сформулировать следующим образом: даже в том случае, когда мы используем прерывания, остается беспокойство, не выполняет ли программа какие-либо операции с предыдущей строкой в то время, когда следующая строка уже полностью введена. Конечно, в среднем, программа просто обязана не отставать от ввода с клавиатуры; тем не менее может возникнуть ситуация, при которой обработчик строки случайно затратит много времени, и вам потребуется временный буфер более чем на одну строку. Одно решение этой проблемы — скопировать информацию во второй буфер или поочередно обращаться к каждому из двух буферов. Изящной альтернативой является организация входного потока в виде очереди, устроенной как кольцевой буфер, в котором два указателя обеспечивают извлечение очередного входного символа, а предыдущий символ удаляется. Обработчик прерываний продвигает вперед входной указатель, а обработчик строки продвигает выходной указатель. Подобный кольцевой буфер как правило имеет емкость 256 байт, что позволяет поддерживать обработку нескольких строк.
Третье замечание относится к обработчику прерываний самому по себе. Обычно чем он короче и проще, тем лучше, например, в нем возможна установка флажков для указания на необходимость выполнения в главной процедуре более сложных операций. Если обработчик прерываний будет долго переводить дух после каждого прерывания, вы рискуете потерять данные, источником которых являются другие устройства, вырабатывающие прерывания, поскольку в то время, когда ЦП обрабатывает прерывание, другие прерывания запрещены. В такой ситуации выход заключается в том, чтобы вновь разрешить обработку прерываний в вашем собственном обработчике командой STI после того, как будут выполнены критические отрезки программы, которые должны выполняться в первую очередь. Затем, если возникло прерывание, ваш обработчик прерываний будет сам прерван. Поскольку флажки и адреса возврата сохраняются в стеке, программа сумеет найти обратную дорогу, сначала в ваш обработчик, а затем в главную программу.
10.11. Прерывания в целом
Наш пример с клавиатурой демонстрирует суть прерываний, которые являются внезапными аппаратно вырабатываемыми запросами от периферийных устройств, вызывающими программную передачу управления специализированной программе обработки прерывания (которая обычно выполняет программно-управляемый ввод-вывод), а затем возврат управления в ту часть программы, выполнение которой было прервано.
Другим примером устройств, использующих прерывания, являются часы реального времени, в которых периодически (часто 10 раз в секунду, но в ПЭВМ типа IBM PC 18,2 раза в секунду) вырабатываемое прерывание «подталкивает» подпрограмму определения текущего времени; еще одним примером является параллельный интерфейс печатающего устройства, который вырабатывает прерывания всякий раз, когда готов новый символ. Используя прерывания, такие периферийные устройства позволяют компьютеру одновременно выполнять другие задания; вот почему вы можете работать с текстовым редактором, пока ваша ПЭВМ печатает файл (и при этом еще и отсчитывает текущее время).
IBM PC, однако, не иллюстрирует всех возможностей прерываний. Как мы видели, имеются 6 линий IRQ на магистрали, каждая из которых может быть задействована только одним устройством, использующим прерывания. Линии IRQ пронумерованы в соответствии с приоритетом; в том случае, когда вырабатываются несколько прерываний, первым отрабатывается то, номер которого меньше. Четыре из IRQ-линий предопределены для таких устройств, как последовательный порт (IRQ4), жесткий диск (IRQ5), гибкий диск (IRQ6) и порт печатающего устройства (IRQ7), оставляя неиспользуемыми только IRQ2 и IRQ3 [линии, соответствующие двум другим, используемым в IBM PC уровням IRQ, даже не выведены на магистраль, а используются на системной плате для обеспечения работы таймера с частотой пересчета 18,2 Гц (IRQ0) и клавиатуры (IRQ1)]. В том случае, если вы хотите дополнительно подключить стример или локальную сеть, придется использовать IRQ2 и IRQ3. Более того, прерывания отрабатываются по фронту сигнала, что делает тщетным какие бы то ни было разумные попытки использовать проводное «ИЛИ» для того, чтобы подключить несколько периферийных устройств к одной IRQ-линии.
Общие линии прерываний. Обычный протокол обработки прерываний, применяемый во многих компьютерах, обходит подобные ограничения. Посмотрите на рис. 10.13.
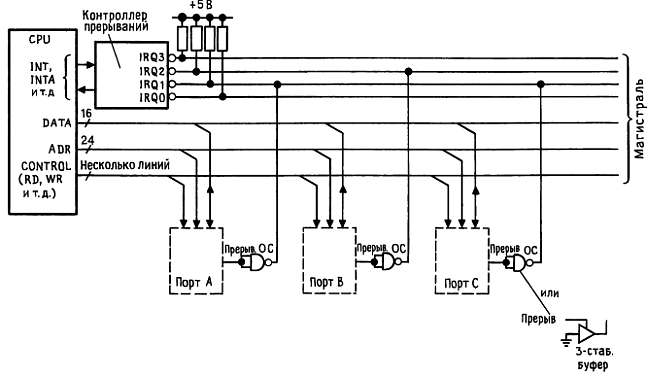
Рис. 10.13. Линии прерываний, совместно используемые несколькими устройствами.
Имеется несколько приоритетных линий IRQ-типа; здесь на входах ЦП (или других узлов, непосредственно с ними связанных) используется отрицательная логика. Для того чтобы сформировать сигнал прерывания, вы должны задать низкий уровень потенциала на одной из IRQ'-линий, используя, как показано, микросхему с открытым коллекторным выходом (или с тремя выходными состояниями). (Отметим хитрость, которая заключается в использовании элемента с трехстабильным выходом в качестве имитатора элемента с открытым коллектором.) Линии IRQ', каждая из которых подключена к нагрузочному резистору, используются несколькими периферийными устройствами совместно, так что к каждой IRQ'-линии можно подключить столько устройств, сколько захочется; в нашем примере два порта совместно используют IRQL Вообще говоря, более «нетерпеливое» устройство следует подключать к IRQ'-линии с более высоким приоритетом.
Поскольку линии IRQ' используются совместно, всегда может возникнуть прерывание, вызванное еще одним устройством в то же время и на той же линии (где уже выставлено прерывание). Центральный процессор должен знать, чем инициировано прерывание для того, чтобы передать управление соответствующему обработчику. Для этого существуют два пути - простой и сложный. Простой путь называется автовекторизованным опросом и используется практически повсеместно (хотя и не в IBM PC). Это делается следующим образом.
Автовекторизованный опрос. На одной плате с ЦП расположены некоторые электронные схемы (для примера мы возьмем электронные узлы, описываемые в гл. 11), которые инструктируют микропроцессор, что ему надо делать для поддержания режима автовекторизации, которая организована подобно тому, что сделано в IBM PC-каждый уровень прерывания вызывает передачу управления, адресуемую с помощью вектора, соответствующим образом расположенного в младших адресах памяти. Например, для МП серии 68000, с которой мы встретимся в гл. 11, существует 7 уровней приоритетных прерываний, которые адресуются 4-байтовыми указателями, располагаемыми в 28-ми (7x4) ячейках памяти с 64Н по 7FH. Адрес вызова обработчика прерываний вы записываете в эти ячейки как в вышеприведенном примере. Например, 4-байтовый адрес для обработчика, соответствующего 3-му уровню прерывания, вы должны записать в ячейки памяти с адресами (в 16-ричной форме) с 6С по 6F.
Перейдя в обработчик, вы знаете, какой уровень прерываний вы обслуживаете; вам только неизвестно, какое конкретно устройство инициировало прерывание. Для того чтобы выяснить, вы просто должны проверить регистры состояний каждого из устройств, подключенных к линии, соответствующей этому уровню прерываний (устройство никогда не должно выставлять запрос на прерывание без дополнительной установки одного или более битов состояний, которые можно считать). Если бит установлен, показывая, что надо бы что-то сделать, вы делаете то, что надо, и еще заботитесь о сбросе сигнала IRQ'. Некоторые устройства (такие, как клавиатура) сами сбрасывают в исходное состояние сигнал прерывания, когда осуществляется чтение данных, тогда как другие могут потребовать передачи специального байта по некоторому адресу порта ввода-вывода.
Если устройство, которое вы обслуживаете, было единственным источником прерываний данного уровня, то теперь, после передачи управления обратно в прерванную программу и продолжения ее выполнения, сигнал IRQ' будет установлен в высокое состояние. Однако если существовало второе устройство, выработавшее прерывание того же уровня, то сигнал на IRQ'-линии будет по-прежнему оставаться в низком состоянии (с помощью приводного «ИЛИ») и после возврата управления из обработчика прерываний ЦП немедленно адресуется к тому же самому вектору и соответственно обработчику. При этом путем опроса будет обнаружено другое устройство, инициировавшее прерывание, выполнено то, что надо и управление будет вновь передано прерванной программе. Отметим, что порядок, в котором вы опрашиваете регистры состояний, эффективно устанавливает программный приоритет, дополнительно к аппаратному приоритету нескольких IRQ'-уровней.
Подтверждение прерывания. Мы не можем проститься с прерываниями без того, чтобы не упомянуть о более сложной процедуре идентификации источника прерывания — подтверждении прерывания. При этом ЦП не должен опрашивать регистры состояний возможных кандидатов, поскольку устройство, инициирующее прерывание, сообщает по запросу ЦП свое имя. Устройство осуществляет это, устанавливая «вектор прерывания» (обычно-уникальный 8-разрядный код) на шине данных, в ответ на сигнал подтверждения прерывания, вырабатываемый ЦП в процессе реализации прерывания. Необходимые сигналы вырабатывает почти каждый МП. Последовательность событий такова: а) ЦП замечает ожидающее прерывание; б) ЦП завершает выполнение текущей команды, затем вырабатывает (1) сигналы магистрали, говорящие о прерывании, (2) определяет уровень прерывания (по младшим разрядам шины адреса), а также (3) вырабатывает подобные сигналам чтения строб-сигналы, которые приглашают устройство, инициировавшее прерывание, идентифицировать себя; в) устройство отвечает на такой набор сигналов магистрали, выставляя свой идентификатор (вектор прерывания) на шину данных; г) ЦП считывает вектор и передает управление обработчику прерываний, соответствующему прерывающему устройству; д) программная часть обработчика прерываний, как в нашем последнем примере, считывает флажки, получает и передает данные и т. д. В число прочих обязанностей обработчика прерываний входит наблюдения за тем, чтобы устройство, затребовавшее прерывание, не «забыло» потом его отменить; е) в конце концов обработчик прерываний возвращает управление той программе, выполнение которой было прервано.
Возможно, проницательные читатели заметили слабое место в изложенной процедуре. В частности, она рассчитана на то, что только одно устройство выставляет свой вектор, тогда как одному IRQ-уровню могут соответствовать несколько устройств, которые вырабатывают запросы на прерывание одновременно. Традиционный метод обработки прерываний в такой ситуации заключается в том, что на магистрали формируется дополнительный сигнал (называемый INTP, приоритет прерывания), необычность которого состоит в том, что линия магистрали, соответствующая этому сигналу, не является общей для устройств, подключенных к магистрали, а, наоборот — проходит через схемную часть интерфейса каждого устройства, пронизывая все интерфейсы, начиная с ближайшего к ЦП устройства с наивысшим уровнем приоритета. На цветистом языке электроники такая конструкция называется daisy chain (дейзи-цепочка, или шлейфовое соединение). Правило, в соответствии с которым аппаратная логика обрабатывает сигнал INTP, следующее: в том случае, если вы не запрашивали прерывание на том уровне, требующем подтверждения, пропустите сигнал INTP к следующему устройству без изменения; если вы хотите подтвердить прерывание на данном уровне, поддерживайте низкий уровень сигнала INTP, выходящего из вашего устройства.
Правило, в соответствии с которым надо теперь выставить вектор, выглядит следующим образом. Как только будет выработан вопрос от ЦП, установите код вашего вектора на шине данных только в том случае, если а) прерывание ожидает на том уровне, который требует подтверждение и б) на входе вашего устройства сигнал INTP имеет высокий уровень. Это гарантирует, что только одно устройство выставит свой вектор; таким образом, также устанавливается цепочка последовательных приоритетов для каждого IRQ-уровня, при этом устройство, электрически ближайшее к ЦП, будет обслуживаться в первую очередь. В таких компьютерах, где применяется подобная схема, для того, чтобы пропустить сигнал INTP через неиспользуемые разъемы магистрали, применяются малогабаритные разъемные замыкатели. Не забудьте их удалить, когда будете устанавливать дополнительную интерфейсную плату (а затем не забудьте их вернуть на место, когда будете отключать соответствующую плату!).
У метода подтверждения прерывания, реализуемого с помощью последовательной дейзи-цепочки, имеется изящная альтернатива: вместо того, чтобы пропускать сигнал через каждый возможный источник прерываний, вы соединяете каждое подобное устройство отдельной линией с приоритетным шифратором (см. разд. 8.14), который, в свою очередь, подтверждает прерывание, идентифицируя наиболее приоритетное из устройств прерывания. Такая схема исключает суету с перетыканием замыкателей. Детально мы это обсудим в разд. 11.4 (рис. 11.8).
В большинстве микрокомпьютерных систем описанная только что организация подтверждения запроса прерывания не используется в полной мере. В конце концов при 8-ми уровневой автовекторизации можно обслужить 8 устройств — источников прерываний без опроса и в несколько раз большее их количество с опросом. Только в больших компьютерных системах, где требуется быстрая реакция при наличии десятков устройств, которые вырабатывают прерывания, возможно, вы поддадитесь искушению усложнить протокол подтверждения прерывания, либо используя аппаратно реализованную последовательную дейзи-цепочку приоритетов, либо — параллельное приоритетное кодирование.
Однако важно понимать, что даже простые компьютеры могут использовать внутреннее векторизованное подтверждение прерывания. Например, простая 6-ти уровневая автовекторизованная схема прерываний IBM PC, как она представляется пользователям магистрали, на самом деле поддерживается микросхемой программируемого контроллера прерываний типа 8259, которая размещается вблизи ЦП и генерирует надлежащую последовательность подтверждений прерывания, описанную ниже. Это необходимо, так как МП 8086 (и его «наследники») не могут сами по себе использовать автовекторизацию. С другой стороны, МП популярной серии 68000 могут использовать автовекторизацию всего лишь с использованием одной дополнительной микросхемы (см. гл. 11).
Маскирование прерываний. В нашем простом примере с клавиатурой мы включили триггер таким образом, что прерывания клавиатуры могут быть заблокированы, даже несмотря на то, что контроллер типа 8259 позволяет выключать («маскировать») каждый уровень прерывания в отдельности. Мы поступили таким образом, чтобы какое-нибудь другое устройство могло затем использовать IRQ2. Для магистрали с совместно используемыми IRQ'-линиями (чувствительными к уровню) особенно важно сделать каждый источник прерываний маскируемым с помощью бита выходного порта ввода-вывода. Например, порт печатающего устройства обычно вырабатывает прерывание всякий раз, когда его выходной буфер пуст («дайте еще данных»); но после завершения печати этот запрос уже не нужен. Очевидное решение заключается в том, чтобы выключить прерывания печатающего устройства. Поскольку могут быть другие устройства, «захватившие» тот же уровень прерываний, надо не маскировать целиком весь уровень, а передать бит в порт печатающего устройства для того, чтобы блокировать его прерывание.
Как IBM PC это делает. Используемый в IBM PC МП 8086/8 в самом деле использует полный протокол подтверждения векторизованных прерываний. Однако для простоты проектировщики IBM PC использовали микросхему контроллера прерываний 8259 на системной плате. Эта микросхема используется следующим образом. К ней подключены линии IRQ от устройств ввода-вывода, расположенных на вставных печатных платах (где вырабатываются соответствующие запросы на прерывания), сам же контроллер соединен с линиями данных и управления собственно МП. Когда контроллер получает от внешнего устройства запрос на прерывание по линии IRQ, он выясняет его приоритет и осуществляет весь комплекс действий, связанных с формированием соответствующего вектора на шине данных. Он имеет регистр маски (доступный через порт ввода-вывода 21Н) так, что вы можете запретить произвольный набор прерываний.
Контроллер типа 8259 позволяет выбирать (программным образом) способ формирования прерывания либо по уровню, либо по фронту соответствующего сигнала на входных линиях IRQ; выбор осуществляется с помощью записи байта в управляющий регистр (порт ввода-вывода 20Н). К сожалению, конструкторы PC решили использовать формирование по фронту, возможно из-за того, что это несколько упрощает формирование прерываний (например, можно непосредственно подать выходной прямоугольный сигнал таймера реального времени на линию IRQ0). Если же вы вместо этого выбрали способ формирования прерываний по уровню сигнала, вы можете «повесить» на каждую IRQ'-линию множество устройств, вырабатывающих прерывания и программно опрашивать их так, как это было описано выше. К несчастью, базовая система ввода-вывода PC (ROM BIOS) и операционная система (за исключением аппаратной части) предполагают формирование по фронту, так что выбор окончателен. (Почти все остальные компьютеры, включая даже «потомков» PC и PC/AT, используют формирование прерываний по уровню.)
Существует частичное решение этой проблемы. Постольку, поскольку IRQ- линия доступна, вы можете объединить на одной плате PC несколько устройств, вырабатывающих прерывания, и логическую схему, которая формирует прерывания для соответствующей IRQ-линии по фронту; для этого можно даже воспользоваться дополнительным контроллером типа 8259 (порты ввода-вывода которого должны быть доступны ЦП). Но поскольку устройство, вырабатывающее прерывание, должно знать о каждом из остальных устройств, такую схему нельзя использовать при независимом подключении внешних устройств. Более того, вы по-прежнему вынуждены использовать по одной IRQ-линии на плату внешних устройств, и сложную систему так построить трудно: в IBM PC имеются только два незадействованных IRQ-уровня.
Программные прерывания. Микропроцессоры серии Intel 8086 имеют команду (INT n, где n = 0… 255), которая позволяет вам осуществить векторизованную передачу управления того же рода, что и настоящее аппаратное прерывание. В самом деле, среди 256 возможных векторов переходов имеются и соответствующие 8 уровням IRQ-запросов аппаратных прерываний (с ΙΝΤ 8 по ΙΝΤ 15, чтобы быть точным). Таким образом, вы можете организовать программное прерывание из некоторой программы. IBM PC использует такие программные прерывания для того, чтобы разрешить вам взаимодействовать с операционной системой и различными программами, «зашитыми» в ПЗУ. Например, INT 5 пересылает копию экрана на печатающее устройство. Особенно важно применение INT 21Н, поскольку это прерывание обеспечивает вызов системных функций: вы сообщаете системе, какую из системных функций хотите использовать, записывая соответствующее число в регистр АН прежде, чем выполнить INT 21Н.
Не следует путать такие программные прерывания с аппаратными прерываниями, вырабатываемыми внешними устройствами, о чем мы говорили выше. Выполнение программных прерываний — это искусный прием использования векторизованной передачи управления из программы пользователя системному программному обеспечению. Но такие прерывания не являются настоящими прерываниями в смысле аппаратно вырабатываемых запросов внешних автономных устройств. Напротив, вы можете встроить эти прерывания в свою программу, вы знаете, когда они произойдут (вот почему вы можете передавать аргументы через регистры ЦП) и они являются всего навсего реакцией (почти такой же, какая следует в случае «истинного» прерывания) ЦП на свою собственную команду. Можете считать программные прерывания мудрым способом расширения набора команд ЦП.
10.12. Прямой доступ в память
Встречаются ситуации, когда данные должны быть переданы от устройства или в устройство очень быстро. Классическим примером является быстрое устройство массовой памяти, например диск или магнитная лента, а также такие приложения, связанные со сбором данных в реальном времени, как многоканальный амплитудный анализ. Программная передача каждого отсчета, инициируемая по прерыванию, в таком случае будет неудобной и, возможно, слишком медленной. Например, данные считываются с гибкого диска с высокой плотностью записи со скоростью около 500 Кбит/с или 1 байт каждые 16 мкс. Если соблюдать все описанные этапы обработки запроса на прерывание, данные почти наверняка будут пропущены, даже если гибкий диск будет единственным источником прерываний в компьютере; с несколькими подобными устройствами ситуация становится безнадежной. Еще хуже дело обстоит с жестким диском, для которого типичное время, затрачиваемое на передачу байта, составляет 2 мкс, что полностью исчерпывает возможности программируемого ввода-вывода. Такие устройства, как диски и магнитные ленты (не говоря уж об упомянутых сигналах и данных в реальном масштабе времени), не могут остановиться на полпути так, что требуется метод, обеспечивающий возможно более быструю реакцию и высокую общую скорость передачи данных. Даже для внешних устройств с низкой средней скоростью передачи данных может требоваться малое время реакции, т. е. время от начального запроса до собственно передачи данных.
Решением этих проблем является прямой доступ в память (ПДП), метод непосредственной связи внешнего устройства с памятью. В некоторых микрокомпьютерах (в том числе и IBM PC) такая связь фактически поддерживается аппаратным устройством (архитектурой ЦП), но не это главное. Важным моментом является то, что при передаче данных отсутствует программирование; байты передаются между памятью и внешним устройством по магистрали, без участия программы. Единственным влиянием на программу является некоторое замедление ее работы, поскольку режим ПДП «захватывает» такты магистрали, которые в противном случае могли бы быть использованы для доступа к памяти при выполнении программы. Аппаратная реализация интерфейса, поддерживающего режим ПДП, сложна, не следует без необходимости использовать этот режим. Однако полезно знать потенциальные возможности, поэтому мы вкратце опишем, что необходимо для построения интерфейса, поддерживающего режим ПДП. Как и в случае с прерываниями, конструкторы IBM PC упростили протокол ПДП; основную работу выполняет контролллер ПДП, расположенный на системной плате, что делает протокол ПДП сравнительно простым. Однако интерфейсы, поддерживающие режим ПДП, обычно оказываются машинно-зависимыми и сложными. Сначала мы поясним функционирование более употребительного метода ПДП с управлением сигнала магистрали, а затем — упрощенный протокол ПДП для PC.
Типовой протокол ПДП. При пересылках данных в режиме ПДП внешние устройства получают доступ к магистрали с помощью специализированных линий «запроса магистрали» (которые также, как IRQ-линии, имеют приоритеты), являющихся составной частью магистрали. Центральный процессор разрешает и ПДП и отдает управление адресами, данными и строб-сигналами. Затем внешнее устройство выставляет адреса памяти на магистраль и либо передает, либо принимает данные побайтно, синхронизуясь с устанавливаемыми им же строб-сигналами; другими словами, внешнее устройство «захватывает» магистраль и работает как ЦП, непосредственно пересылая данные. Устройство, которое в режиме ПДП управляет магистралью, отвечает за вычисление адресов (как правило, непрерывную область адресов, вырабатываемых с помощью двоичного счетчика) и подсчет количества переданных байтов. Обычно для этого достаточно иметь счетчик байтов и адресный счетчик в составе интерфейса.
Эти счетчики первоначально загружаются на ЦП, посредством программируемого ввода-вывода, для того, чтобы предустановить требуемые параметры передачи данных в режиме ПДП. По команде ЦП (посредством записи управляющего бита с помощью программируемого ввода-вывода) интерфейс формирует требование ПДП и начинает пересылать данные. Интерфейс может освобождать магистраль в промежутки времени между передачей байтов (позволяя тем самым ЦП «урвать» время и выполнить несколько команд), или он может вести себя более эгоистично, захватывая магистраль на все время передачи блока данных. После того, как все данные переданы, интерфейс освобождает магистраль до следующего раза и сообщает программе о том, что все закончено, устанавливая бит состояния и вырабатывая прерывание, после чего ЦП может решить, что делать дальше.
Загрузка данных или программ с диска-наиболее общий пример передачи данных в режиме ПДП. Выполняемая программа запрашивает какие-нибудь файлы по именам; операционная система (подробнее - чуть позже) преобразует эти имена в команды программируемого вывода данных для управляющего (или командного) регистра интерфейса диска, регистра счетчика байтов и адресного регистра (описывая с какого места на диске, и сколько байтов надо считать, и в какую область памяти их поместить). Затем интерфейс диска отыщет необходимую область на диске, сформирует запрос ПДП и начинает передавать блоки данных в заданную область памяти. Когда это будет выполнено, интерфейс установит определенные биты в регистре состояния для того, чтобы обозначить завершение работы и затем инициирует прерывание. Центральный процессор, который тем временем выполняет другие команды (или, возможно, как раз ожидает данных с диска), «откликается» на прерывание, по содержимому регистра состояния интерфейса диска определяет, что данные находятся в памяти и затем переходит к выполнению следующих команд. Таким образом, программируемый ввод-вывод (простейший вариант ввода-вывода) был использован для инициализации режима ПДП, собственно ПДП (перехватывающий у ЦП циклы магистрали) был использован для быстрой передачи данных, а прерывание было использовано для того, чтобы дать знать компьютеру о том, что передача выполнена. Такого рода иерархия ввода-вывода — исключительно частый прием, особенно для устройств массовой памяти; максимальная скорость передачи данных по типовой микрокомпьютерной магистрали в режиме ПДП может составлять от 1 до 10 млн. слов в секунду.
ПДП в IBM PC. Компьютер IBM PC, который в общем-то прост, поддерживает упрощенный протокол ПДП. На системной плате установлен контроллер ПДП (Intel 8237) со встроенными адресным и байтовым счетчиками, а также дополнительными логическими схемами для блокировки ЦП и перехвата управления магистралью. Таким образом, внешнее устройство, которое хочет выполнить ПДП, не должно вырабатывать адреса и управлять магистралью. Вместо этого он сигнализирует контроллеру с помощью одной из трех DRQ1-DRQ3 линий запроса ПДП; контроллер откликается по соответствующей линии DACK0-3' (подтверждение ПДП). Затем контроллер управляет передачей данных, формируя адрес и соответствующие строб-сигналы, синхронно с формированием внешним устройством данных для передачи в память (или синхронно с приемом данных из памяти). Во всем этом процессе память не замечает ничего необычного, поскольку генерация адресов и строб-сигналов управления памятью (MEMW' или MEMR'), которая обычно поддерживается ЦП, в данном случае поддерживается контроллером 8237 и, если ПДП сопровождает передачу данных в память, данные формируются внешним устройством. С другой стороны внешние устройства «знают» все особенности того, как надо формировать запрос ПДП (и что делать при получении подтверждения посредством сигнала DACK'); таким образом, когда контроллер ПДП выставляет сигнал IOR' (или IOW'), внешнее устройство вырабатывает (или принимает) соответствующие байты. Вы можете удивиться, как это такой простодушный, сторонний наблюдатель, как внешнее устройство, не запутается во время ПДП, когда выставлены и строб- сигналы ввода-вывода, и адреса, причем эти адреса являются адресами в памяти, установление которых сопровождается строб-сигналами управления памятью MEMW' или MEMR', генерируемыми контроллером; эти адреса не имеют никакого отношения к портам ввода-вывода.
Секрет здесь заключается в нашем старом знакомом-сигнале AEN, который добавлен к магистрали специально только для решения подобных проблем. Уровень сигнала AEN во время передачи данных в режиме ПДП устанавливается высоким, и функции разрешения адресации всех портов ввода-вывода должны вычисляться как логическое произведение с низким уровнем сигнала AEN для того, чтобы предотвратить ложную реакцию при адресации памяти в режиме ПДП.
Даже при использовании отдельной микросхемы контроллера вам все еще надо задать начальный адрес, количество байтов и направление передачи данных для грядущего режима ПДП. Эти параметры заносятся в контроллер 8237, который обязан иметь набор регистров, куда из ЦП (с помощью программируемого ввода-вывода) можно записать соответствующие значения. Настройка ПДП осуществляется весьма просто (см. книгу Эггбрехта для более детального ознакомления), если не считать того, что, как и у большинства микросхем БИС, здесь также имеется ошеломляющее разнообразие выбора различных режимов работы (посимвольная передача, поблочная передача и т. п.). К счастью IBM PC достаточно примитивна и позволяет вам использовать только режим посимвольной передачи, при котором каждый запрос DRQ сопровождается передачей лишь одного байта. Если вы настаиваете на передаче целого блока данных, поддерживая сигнал DRQ в высоком состоянии, контроллер 8237 освобождает магистраль на один цикл ЦП между циклами ПДП; это позволяет компьютеру сохранять работоспособность даже в том случае, когда у вас такое «прожорливое» внешнее устройство, что оно старается «заграбастать» магистраль полностью.
Стандартная PC обладает довольно скромными возможностями режима ПДП-около 2 мкс на передаваемый байт. По сравнению с количеством прерываний количество каналов ПДП в IBM PC меньше. Для шины ввода-вывода доступны три канала DRQ1-DRQ3 (DRQ0 уже задействован на внутренние нужды — для регенерации динамической памяти): DRQ1 используется жестким диском, а DRQ2 — гибким. На все остальное остается DRQ3.
10.13. Сводный перечень сигналов магистрали IBM PC
На рассмотренных нами примерах-программируемого ввода-вывода, прерываний, ПДП-мы познакомились с большинством сигналов магистрали, поступающими на плату внешнего устройства IBM PC В табл. 10.1 (и на рис. 10.14) приведен полный перечень сигналов магистрали с цоколевкой разъема. Для полноты изложения ниже описан каждый из этих сигналов, начиная с тех, с которыми мы уже встретились.
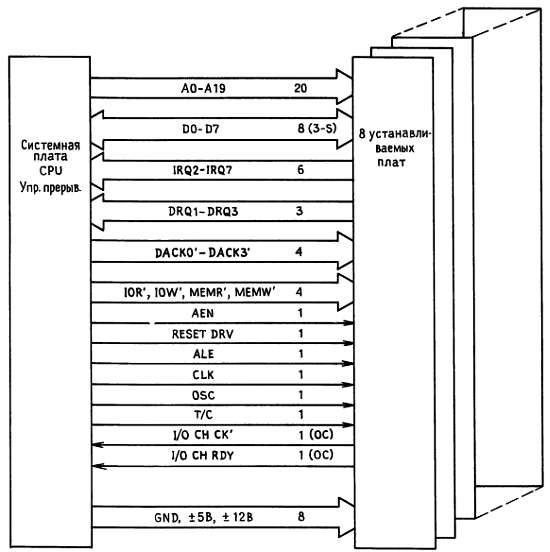
Рис. 10.14. Магистраль IBM PC.
А0-А19. Шина адреса. Два состояния, работает только на запись, действующий уровень сигнала-высокий. Все 20 разрядов используются для адресации памяти (совместно с сигналами MEMR' и MEMW', которые играют роль строб-сигналов, по аналогии с сигналами IOR' и IOW'), но только 16 младших разрядов используются при адресации ввода-вывода, (64 К адресов портов); устройства ввода-вывода должны осуществлять выборку адреса только при низком уровне сигнала AEN.
Важное замечание: ввод-вывод в пределах системной платы предусматривает адресацию только десятью младшими разрядами, используя при этом лишь адреса 000H-1FFH, поэтому адреса устройств ввода-вывода должны иметь в своих младших разрядах коды в диапазоне 200H-3FFH. Вы можете поступить умнее, используя наряду со свободными 10-разрядными адресами еще и 6 старших бит, расширив таким образом адресное пространство портов ввода-вывода до 64К.
D0-D7. Шина данных. Три состояния, двунаправленная, действующий уровень сигнала-высокий. Данные выставляются ЦП при записи в память или в порт ввода-вывода: выставляются памятью при чтении из памяти, в том числе и при ПДП; выставляются портом ввода-вывода при чтении из порта, в том числе и в память при ПДП.
IOR', IOW', MEMR', MEMW'. Строб-сигналы данных. Два состояния являются выходными (по отношению к ЦП), действующий уровень сигнала — низкий. Формируются ЦП при чтении или записи. При записи данные должны быть зафиксированы по спаду (положительному) и при надлежащем адресе; при чтении должны быть выставлены одновременно со строб-сигналом при заданном адресе.
AEN. Разрешение адреса. Два состояния, является выходным (по отношению к ЦП), действующий уровень сигнала — высокий. Вырабатывается ЦП во время циклов ПДП. Порты ввода-вывода не должны дешифровать адрес при наличии сигналов IOR', IOW', за исключением тех случаев, когда порты ввода-вывода принимают сигнал DACK и используют сигналы IOR' и IOW' для стробирования байтов данных ПДПН.
IRQ2-IRQ7. Запрос прерывания. Два состояния, является входным (по отношению к ЦП), действующим является нарастающий фронт. Вырабатывается устройством, запрашивающим прерывания. Приоритеты установлены таким образом, что IRQ2 имеет наивысший, a IRQ7 — наинизший приоритет. Контроллер прерываний 8259 допускает их маскирование, устанавливаемое ЦП посредством записи в порт по адресу 21Н. Каждый уровень IRQ может быть использован одновременно только одним устройством.
RESET DRV. Предустановка драйвера. Два состояния, является выходным (по отношению к ЦП), действующий уровень — высокий. Вырабатывается ЦП при включении электропитания. Используется для предустановки устройства ввода-вывода в заданное начальное состояние.
DRQ1-DRQ3. Запрос ПДП. Два состояния, является входным (по отношению к ЦП), действующий уровень — высокий. Вырабатывается устройством ввода-вывода, которое запрашивает канал ПДП. Приоритеты установлены таким образом, что DRQ1 имеет наивысший, a DRQ3 — наинизший приоритеты. Подтверждается сигналами DACK1'-DACK3'.
DACK0'-DACK3'. Подтверждение ПДП. Два состояния, является выходным (по отношению к ЦП), действующий уровень — низкий. Вырабатывается ЦП (или контроллером ПДП) для того, чтобы обозначить подтверждение соответствующего запроса ПДП.
ALE. Разрешение фиксации адреса. Два состояния, является выходным (по отношению к ЦП), действующий уровень — высокий. Микропроцессор Intel 8088 использует мультиплексируемую шину данные/адрес, и этот сигнал соответствует строб-сигналу МП, используемому регистрами-фиксаторами на системной плате для фиксации адреса. Может быть использован в качестве сигнала начала цикла ЦП; обычно при проектировании ввода-вывода игнорируется.
CLK. Тактовый сигнал. Два состояния, является выходным (по отношению к ЦП). Это-тактовый сигнал ЦП; он асимметричен, 1/3 периода поддерживается высокий уровень, а 2/3 — низкий. Исходные PC работали на частоте 4,77 МГц, сейчас используются более высокие частоты. Сигнал CLK применяется для синхронизации состояний ожидания при запросах (с использованием сигнала I/O CHRDY) для того, чтобы удлинить цикл ввода-вывода для медленных устройств.
OSC. Тактовый сигнал. Два состояния, является выходным (по отношению к ЦП). Этот сигнал представляет собой меандр с частотой 14,31818 МГц, который может использоваться (будучи поделенным на 4) для синхронизации работы цветного дисплея.
Т/С. Завершение передачи. Два состояния, является выходным (по отношению к ЦП), действующим является высокий уровень. Этот сигнал сообщает порту ввода-вывода, что передача блока данных в режиме ПДП завершена. Устройство, выполняющее ПДП, должно обрабатывать этот сигнал по совпадению с сигналом DACK' для используемого канала, поскольку сигнал Т/С вырабатывается независимо от того, по какому из каналов ПДП завершилась передача блока.
I/O СН СК'. Проверка канала ввода-вывода. Открытый коллекторный выход, является входным (по отношению к ЦП), действующий уровень-низкий. Инициирует прерывание с наивысшим приоритетом (немаскируемое прерывание); используется для того, чтобы сигнализировать о состоянии ошибки в каком-то из внешних устройств. Центральный процессор определяет «возмутителя спокойствия» опросом внешних устройств (см. разд. 10.11); следовательно, каждое устройство, которое вырабатывает сигнал I/O СН СК', должно иметь бит состояния, который может быть прочитан ЦП.
I/O СН RDY. Готовность канала ввода-вывода. Открытый коллекторный выход, является входным (по отношению к ЦП), действующий уровень — высокий. Формирует состояние ожидания, если перед вторым фронтом сигнала CLK цикла процессора (в цикле обычно 4 такта сигнала CLK) уровень сигнала I/O СН RDY установлен низким. Используется для удлинения цикла магистрали для медленных устройств ввода-вывода или при обращении к памяти.
GND,+5VDC, —5VDC, +12VDC, -12VDC. «Земля» и уровни постоянных напряжений питания. Регулируемые уровни постоянного напряжения, передаваемые по магистрали для питания внешних устройств, размещенных на вставных платах. Изучите описание вашего компьютера для того, чтобы выяснить ограничения на суммарную потребляемую электрическую мощность, которая зависит от модификации компьютера. Вообще говоря, мощности должно хватить для питания всего того, что вы подключите с помощью разъемов расширения магистрали.
10.14. Синхронный и асинхронный протоколы магистрали
Протокол ввода-вывода, описанный нами ранее, является примером синхронного обмена данными; данные выставляются на шину или принимаются с нее синхронно со стробирующими сигналами, которые генерируются ЦП (или контроллером ПДП). Этот метод отличается простотой, однако он чреват неприятностями в случае использования протяженных длинных шин, поскольку большое время распространения сигнала может привести к тому, что данные в операции ввода будут устанавливаться недостаточно быстро, чтобы обеспечить надежную передачу. Собственно говоря, при синхронном протоколе устройство, посылающее данные, так никогда и не узнает, получены ли эти данные! Это может показаться серьезным недостатком, но в действительности компьютерные системы с синхронными магистралями превосходно работают.
Альтернативой является асинхронная магистраль, на которой операция, например, ввода осуществляется следующим образом. ЦП устанавливает адрес порта, а на стробирующей линии (назовем ее, как и раньше, IOR') уровень (не импульс), который показывает адресному устройству, что идет операция ввода. Адресуемое устройство устанавливает данные на линиях DATA, а также уровень, сигнализирующий о наличии достоверных данных (назовем его DTACK', data transfer acknowledged, подтверждение передачи данных). ЦП, обнаружив DTACK', фиксирует («защелкивает») данные и затем снимает уровень IOR'. Как только интерфейс замечает, что линия IOR' переходит в высокое состояние, он снимает сигналы с линий DTACK' и DATA. Другими словами, ЦП заявляет: «Дай мне данные». Периферийное устройство отвечает: «Вот они, бери». Тогда ЦП говорит: «Готово, взял». И, наконец, периферийное устройство завершает диалог: «Отлично! Пойду снова спать». Описанную процедуру иногда называют «рукопожатием», или квитированием. Асинхронный протокол допускает использование длинных шин и позволяет взаимодействующим устройствам убедиться, что данные действительно передаются. Если удаленное устройство будет выключено, ЦП узнает об этом. Собственно говоря, эта информация доступна (через регистры состояния) на магистралях любого вида, и основное достоинство асинхронного протокола заключается в возможности использовать линии связи любой длины за счет незначительного усложнения аппаратуры.
Иногда вам может понадобиться подключить к магистрали относительно медленные интерфейсные ИС; примером может служить ПЗУ с большим временем доступа или даже ОЗУ. Все магистрали предоставляют какие-то средства удлинения цикла магистрали, однако при асинхронном протоколе это происходит само по себе, поскольку цикл магистрали продолжается до тех пор, пока не будет снят сигнал DTACK'. Синхронные магистрали всегда содержат какую-то линию типа HOLD' (в компьютерах PC она называется I/O СН RDY) для организации состояний ожидания и задержки во времени конца цикла. Результирующая длительность цикла всегда увеличивается на целое число тактов генератора ЦП, т. е. на число включенных в цикл «состояний ожидания». Например, стандартная IBM PC имеет тактовую частоту 4,77 МГц (период 210 нc), а длительность обычного цикла магистрали при обращении к памяти составляет 4 тактовых периода (840 нc). Если сигнал I/O СН RDY переводится в низкое состояние при обращении к памяти перед вторым фронтом сигнала CLK и снова переходит в высокое состояние перед третьим, генерируется одно состояние ожидания с удлинением цикла магистрали (а также и сигналов MEMW' или MEMR') до 5 тактов (1050 нc). Удерживая сигнал I/O СН RDY в низком состоянии на протяжении большего числа тактов, вы создаете дополнительные состояния ожидания, вплоть до 10 периодов тактового генератора.
Теперь мы можем открыть тщательно скрываемый секрет про синхронные и асинхронные магистрали: практически все микрокомпьютеры с одним процессором (или, точнее, с одним ведущим на магистрали) являются синхронными, потому что вся синхронизация привязана к единственному генератору ЦП (вроде 4,77 МГц тактового генератора исходных IBM PC). В результате если периферийное устройство задерживает свое подтверждение на «асинхронной» магистрали, цикл всегда удлиняется на целое число тактов ЦП. Разница между синхронными и асинхронными магистралями в действительности заключается в следующем. На «асинхронной» магистрали состояния ожидания включаются в цикл по умолчанию, если только не установлен в низкое состояние сигнал DTACK' (поступающий через проводное ИЛИ), в то время как на «синхронной» магистрали состояния ожидания по умолчанию не возникают; они генерируются лишь если линия проводного ИЛИ (HOLD') устанавливается в низкое состояние. Однако различие не носит лишь семантический характер — «синхронный» протокол не позволяет работать с длинными шинами, потому что в этом случае сигнал HOLD' поступает в ЦП слишком поздно, чтобы удлинить цикл, в то время как на «асинхронной» магистрали ЦП не завершит цикл обмена без вашего разрешения (сигнал DTACK'). Со свойственной нам скромностью мы предлагаем, во избежание недоразумений, пользоваться следующей многообещающей терминологией: если состояния ожидания генерируются на магистрали по умолчанию («асинхронная» магистраль), будем называть ее «с ожиданием по умолчанию» (default-wait); если состояния ожидания возникают только при их запросе («синхронная» магистраль), будем называть ее «с ожиданием по запросу» (request-wait). Магистраль IBM PC характеризуется ожиданием по запросу, а магистраль VME (см. ниже) — по умолчанию.
Процессы на магистрали еще более усложняются в многопроцессорных системах, где управление магистралью переходит из рук в руки. На синхронной магистрали с несколькими ведущими все ведущие должны использовать единый тактовый генератор, в то время как асинхронная магистраль допускает различные тактовые частоты. К счастью для вас, обсуждение многопроцессорных систем выходит за рамки этой книги! Следует отметить обстоятельство, могущее привести к недоразумениям. Вы не добавляете состояния ожидания при работе с медленными периферийными устройствами (например принтером); это следует делать лишь при наличии медленных ИС (скажем, ПЗУ с временем доступа 250 нc или медленной периферийной БИС). Медленная периферия обычно безнадежно медленна (миллисекунды, а не наносекунды); с такими устройствами следует посылать (или принимать) байт на полной скорости магистрали, фиксируя его в регистре байтовой ширины, после чего ожидать прерывания (или, возможно, установки флага состояния), чтобы инициировать следующую передачу на, полной скорости.
10.15. Магистрали других микрокомпьютеров
Для иллюстрации архитектуры микрокомпьютерной магистрали-сигналов на магистрали, разновидностей ввода-вывода, прерываний, прямого доступа к памяти, мы выбрали магистраль IBM PC. Для книги по электронике это оправданный выбор, так как компьютеры типа PC выпускаются повсеместно и широко применяются в технике вообще и в системах сбора данных и управления в частности. К тому же, магистраль PC исключительно проста в объяснении и использовании.
Однако за простоту приходится платить. Магистрали исходных IBM PC свойственны серьезные ограничения, уже упоминавшиеся ранее (например, малое число уровней прерываний и каналов ПДП). Кроме того, магистраль IBM PC имеет по нынешним меркам слишком маленькое адресное пространство (20 бит, и доступны только 640 К), слишком узкую шину данных (8 бит), недостаточную скорость передачи данных (максимально 1,2 Мбайт/с) и невозможность работы с несколькими ведущими шины. Для последующих поколений машин PC фирма IBM разработала улучшенные магистрали, сначала магистраль PC/AT (совместимое усовершенствование исходных PC), а затем новую (и несовместимую!) «микроканальную» магистраль для серии машин PS/2. Вне мира IBM можно найти конкурирующие магистрали конкретных разработчиков (например, Q-bus и VAXBI фирмы DEC), а также типовые магистрали (Multibus, NuBus, VME). Давайте пройдемся по компьютерным магистралям, перечисленным в табл. 10.2.
PC/AT и Micro Channel. Компьютеры IBM PC/AT (сокращение от Advanced Technology, улучшенная технология) появились в 1984 г., а в 1987 г., на вершине популярности, их производство было приостановлено, чтобы уступить место серии машин IBM PS/2, использовавших улучшенную магистраль Micro Channel и призванных одним махом прихлопнуть производителей АТ-аналогов. (Однако машины PC/AT продолжали процветать, поскольку производители их аналогов, как и многие покупатели, сначала игнорировали новинку IBM, улучшенные качества которой требовали несуществующего программного обеспечения.) В PC/AT используется микропроцессор 80286 и расширенная (но совместимая) магистраль исходных PC: дополнительный (и необязательный) разъем для добавочных 8 бит данных, 4 бит адресов и 5 линий IRQ (со срабатыванием, как и прежде, по фронту). В результате 16-разрядная шина данных и более высокая тактовая частота подняли пропускную способность магистрали до 5,3 Мбайт/с, что в сочетании с расширением адресного пространства и увеличением числа уровней прерываний сделали PC/AT весьма серьезным микрокомпьютером. Магистраль PC/AT (иногда называемая Industry Standard Architecture, или ISA - стандартная промышленная архитектура) даже допускает нескольких ведущих на магистрали, хотя ее возможности в этом отношении ограничены. Платы, предназначенные для исходных PC, будут работать и на PC/AT (если они обладают необходимым быстродействием), так как усовершенствования, собранные на дополнительном разъеме, можно игнорировать; в этом случае, конечно, вы возвращаетесь к 8-разрядной шине данных и 20-разрядному адресному пространству. АТ-совместимые компьютеры обычно эксплуатируют свою магистраль ввода-вывода на высоких скоростях, и при использовании старых вставных плат могут возникнуть дополнительные трудности синхронизации.
Магистраль Micro Channel была впервые применена в серии персональных компьютеров второго поколения IBM PS/2, появившихся в 1987 г. Магистраль характеризуется большой шириной шин адресов и данных (до 32 разрядов у моделей с микропроцессором 80386), 11 уровнями разделяемых прерываний (чувствительных к уровню), возможностью работы нескольких ведущих шины и асинхронным протоколом. Платы, подключаемые к магистрали Micro Channel, не содержат запаянных адресов портов ввода-вывода; адреса (вместе с другими конфигурационными характеристиками) назначаются ЦП в процессе загрузки на основе информации, прочитанной в ПЗУ на плате. Это приятное качество избавляет вас от необходимости настраивать каждую плату с помощью микропереключателей или беспокоиться о возможности наложения адресных пространств разных плат. Платы Micro Channel характеризуются очень небольшими геометрическими допусками, что связано с использованием разъемов с расстоянием между контактами всего 1,27 мм.
EISA. Расширенная стандартная промышленная архитектура (Extended Industry Standard Architecture, EISA) явилась ответом производителей АТ-аналогов на наступление магистрали Micro Channel. Магистраль EISA была предложена в 1988 г. девятью фирмами, выпускающими АТ-совместимые компьютеры. Добавив к АТ-магистрали дополнительный разъем, разработчики EISA реализовали многие привлекательные черты магистрали Micro Channel, сохранив совместимость с существующими вставными платами AT. Таким образом, вы можете вставить стандартную плату AT в магистраль EISA и получить обычную машину AT. Однако при использовании с магистралью EISA специально разработанных для нее плат, магистраль поддерживает 32-бит передачу данных (с максимальной скоростью передачи 33 Мбайт/с), 32-бит адресацию памяти, несколько ведущих магистрали, программируемые прерывания по уровню или по перепаду, а также автоматическое конфигурирование платы.
Multibus I и II. Форматы магистрали Multibus, первоначально предложенные фирмой Intel, нашли применение во многих компьютерах. Исходная магистраль Multibus I имеет большие возможности, в том числе 16-разрядную шину данных, 24-разрядное адресное пространство и несколько ведущих на магистрали. Miltibus II предназначена для высокопроизводительных микропроцессорных систем и отличается 32-разрядными шинами адресов и данных, контролем четности, распределенным арбитражем, протоколами передачи сообщений. Магистраль использует 10 МГц тактовый генератор в синхронном режиме и может передавать до 40 Мбайт/с по последовательным адресам в режиме «блочной передачи». Так же, как и некоторые другие сложные магистрали, в Multibus II экономятся контакты путем мультиплексирования данных и адресов на подшине из 32 линий. В Multibus II используются также 96-контактные соединители DIN, укрепленные на платах, вместо торцевых плоских позолоченных соединителей; хорошо разработанный «составной» соединитель на плате обеспечивает большую надежность, и система соединения оказывается нечувствительной к искривлению плат и грубому обращению.
Хотя Multibus II отличается многими преимуществами, гибкость этой магистрали усложняет ее использование. Например, на магистрали отсутствуют обычные прерывания; вы «прерываете» путем запроса на захват магистрали и посылки затем сообщения в процессор о вашем желании прервать его работу! Для простых систем удобнее использовать более простую магистраль Multibus 1 (или какую-то другую того же класса).
NuBus. Это еще одна высокопроизводительная синхронная многопроцессорная магистраль с 32-разрядными мультиплексированными данными и адресами, соединителями DIN и высокой скоростью передачи данных (до 40 Мбайт/с в режиме блочной передачи). Как и в случае Multibus II, прерывания реализуются путем запроса на захват магистрали. Магистраль NuBus используется в старших моделях компьютеров Macintosh, где, к счастью, фирма Apple добавила к каждому разъему линию прерываний. Таким образом, каждый разъем для установки вставной платы имеет назначенный ему вектор; соответствующий обработчик прерываний определяет плату-источник прерывания без процедуры опроса, которая требуется лишь в тех случаях, когда плата содержит несколько прерывающих устройств.
Магистраль VME. Эта магистраль, как и NuBus или Multibus II, предназначена для многопроцессорных 32-разрядных систем. Однако в ней не используются мультиплексированные линии данных/адресов. Нет в ней и главного тактового генератора для синхронной передачи, поскольку для магистрали принят асинхронный протокол; это дает возможность без труда объединять процессоры, работающие с разными скоростями. Магистраль VME включает обычную многоуровневую систему прерываний IRQ-типа, с полным подтверждением прерывания (и линией INTR, образующей последовательную цепочку). Магистраль VME часто рассматривают, как альтернативную по отношению к Multibus; например, исходные компьютеры Sun фирмы Sun Microsystems использовали Multibus, в то время как в более поздних моделях Sun2 и Sun3 применена магистраль VME. Магистрали VME и Multibus II под одобрение фирм Motorola и Intel постоянно выясняют свои отношения в технической прессе с обличительными заявлениями и бранью.
Fastbus и Futurebus. Это весьма высокопроизводительные магистрали, работающие с ошеломляющей скоростью. Магистраль Fastbus использует платы большого размера (14x16 дюйм), ECL — драйверы и протоколы арбитража для работы с несколькими ведущими на магистрали. Сильной стороной этих магистралей является система магистральных взаимодействий с возможностью изощренной «географической» адресации за пределы собственно крейта плат.
Q-bus иVAXBI. Это патентованные магистрали компьютеров фирмы DEC. Магистраль Q-bus, использовавшаяся в машинах LSI-11 и ранних компьютерах Micro VAX, произошла от магистрали Unibus исходных машин PDP-11 фирмы DEC. Q-bus поддерживает 16-разрядные данные и 22-разрядную адресацию, асинхронный протокол с несколькими ведущими и многоуровневые прерывания IRQ-типа. VAXBI является высокопроизводительной магистралью с мультиплексированной 32-разрядной шиной данных/адресов, предназначенной для более совершенных машин VAX серии 8600.
10.16. Подключение к компьютеру периферийных устройств
Интерфейсы обычно изготавливаются в виде печатных плат, либо плат с накруткой (см. гл. 12), предназначенных для вставления в плоские разъемы («слоты») микрокомпьютера. Обычно в микрокомпьютере предусматривается некоторое количество свободных разъемов именно для этой цели (либо занятые разъемы допускают «расширение» и вставление новых плат), причем по всем разъемам разводятся сигналы магистрали и питающие напряжения. Некоторые машины используют «патентованные» магистрали (например IBM PC), другие базируются на стандартных микрокомпьютерных магистралях (например рабочая станция Sun3 с магистралью VME), наконец, в некоторых вообще не предусматривается дополнительных разъемов (например исходные машины Macintosh). Каждая магистраль рассчитана на платы некоторого стандартного размера (или размеров), от крошечных плат IBM PS/2 размером 3,2x11,5 дюйм до гигантских 14,4x15,9 дюйм плат Fastbus. Каждая плата, в зависимости от магистрали, для которой она предназначена, имеет вдоль одного края от 50 до 300 соединений либо в форме позолоченных печатных ламелей, либо в виде многоштырьковых соединителей, припаянных к плате; последние известны под именем «составных» (two-part) соединителей и, как правило, более надежны, чем печатные плоские разъемы. Имеющиеся на рынке интерфейсы для решения стандартных задач (диски, графика, связь, аналоговый ввод-вывод) обычно монтируются на платах, которые вставляются в свободные разъемы машины. Если интерфейс управляет периферийным устройством, они связываются кабелями; в тех случаях, когда у интерфейса очень много входов и выходов (как, например, у цифрового логического анализатора), он может соединяться кабелем с внешней частью в виде панели или коробки, где больше места для разъемов (и дополнительных схем). В любом случае обычно используется гибкий ленточный кабель, причем предусматриваются меры для снижения уровня перекрестных помех на сигнальных и стробирующих линиях.
Один из способов заключается в заземлении каждой второй линии в кабеле; другой предполагает использование гибкого кабеля, скрепленного с гибкой же металлической заземленной подложкой, которая уменьшает индуктивность и помехи и в то же время обеспечивает почти постоянный импеданс кабеля. Для обоих конструкций в продаже имеются многоконтактные «оконечные заземлители», которые подключаются к кабелю путем обжатия; смотрите каталоги AMP, Berg, Т&В Ansley, ЗМ и т. д. Альтернативой ленточному кабелю служит кабель, сделанный из многих скрученных пар, каждая из которых содержит одну сигнальную и одну заземленную линию. Кабель из скрученных пар выпускается во многих модификациях, включая щеголеватый плоский кабель, напоминающий ленточный (кабель Twist-'n-flat — «кручено-плоский» фирмы Allied/Spectra). В кабель через каждые полметра включается плоский нескрученный участок, на который можно надеть обычный обжимающий соединитель для ленточного кабеля. Поскольку для передачи данных между интерфейсной платой и устройством обычно используется протокол со стробированием, защищать все сигнальные линии от наводок нет необходимости. Защита требуется лишь для синхронизирующих импульсов и, других линий стробов и разрешений. Если линии имеют значительную длину, следует использовать согласованные нагрузки и комбинации приемников и драйверов, как это описано в разд. 9.14.
Нестандартные интерфейсы лучше всего выполнять таким же образом, либо путем разработки для них печатной платы, либо используя одну из универсальных интерфейсных плат, выпускаемых такими компаниями, как Douglas, Electronic Solutions и Vector. Эти пустые платы имеют места для подключения микросхем и других компонентов (включая оконечные заземлители для внешних кабелей) как припаиванием, так и накруткой (подробнее об этом см. в гл. 12). Некоторые платы содержат встроенные схемы для взаимодействия с магистралью, включая обслуживание прерываний и даже ПДП.
В некоторых случаях наилучшим решением является разработка интерфейса, частично располагаемого в компьютере, а частично-снаружи, как это показано на рис. 10.15.
Рис. 10.15. Структура разделенного интерфейса.
Тогда «компьютерная» часть интерфейса может включать, например, лишь простой параллельный порт ввода-вывода, либо в виде покупной платы, либо собственной разработки. Кабель, соединяющий две части интерфейса, оказывается простым; если требуется скоростная передача при большой протяженности кабеля, можно использовать высокопроизводительные комбинации драйверов/приемников, обсуждавшиеся в разд. 9.14 (например RS-232 или симметричные микросхемы 75S110, или даже волоконную оптику). Такой подход к конструированию интерфейсов может быть особенно полезен при работе со слабыми аналоговыми сигналами, поскольку в этом случае чувствительные к помехам линейные цепи можно удалить от рева наводок цифровых схем компьютера (и приблизить к источнику аналоговых сигналов); это также позволяет с особым вниманием отнестись к поддержанию «в чистоте» заземленных линий аналогового сигнала.
SCSI, IEEE-488 и другие интерфейсы. В продаже имеются буквально сотни вставных плат для распространенных магистралей вроде IBM PC, Multibus, VME и Q-bus, выполняющих необозримое множество функций. Эти платы недороги и просты в использовании, так что перед разработкой собственной платы вы должны сначала выяснить (а) нет ли такой же платы в продаже и (б) нельзя ли использовать в качестве «резидентной в компьютере» части вашего интерфейса простую плату параллельного порта, как это описывалось в предыдущем разделе. Есть и другая возможность-подключить ваше устройство к компьютеру через стандартный встроенный параллельный порт Centronics либо через последовательный порт RS-232 (см. разд. 10.19 и 10.20). Поскольку эти порты одинаковы на всех микрокомпьютерах, такое решение сделает ваше устройство переносимым, даже на микрокомпьютер с другой магистралью (или вообще без магистрали!). Если ваше устройство подключается к последовательному порту, оно, скорее всего, будет включать собственный микропроцессор, что даст вам право думать о нем скорее как о компьютере, чем о периферийном устройстве. Однако как мы покажем в следующей главе, разработка небольшого прибора, управляемого микропроцессором — дело забавное, простое и недорогое; собственно, нет никаких причин выделять микропроцессор среди других БИС, а их-то вы не колеблясь используете в своем приборе!
Развивая дальше предложенную идею, следует сказать, что имеется целый ряд стандартов на «кабельные интерфейсы», ставшие последнее время весьма популярными. Они называются SCSI (Small Computer System Interface-интерфейс малых компьютерных систем), IPI (Intelligent Peripherals Interface-интерфейс интеллектуальной периферии), ESDI (Enhanced Small-Disk Interface — улучшенный интерфейс малого диска) и IEEE-488 (известный также под именами HPIB и GPIB, General-Pur-Кабель — Внешняя часть интерфейса pose Interface Bus-интерфейсная магистраль общего назначения). Интерфейс SCSI (произносится «скази»), в особенности благодаря обилию дисков и другой периферии, подключаемой непосредственно к порту SCSI, стал стандартным элементом многих микрокомпьютеров. При этом для компьютеров, не имеющих встроенного порта SCSI, выпускаются вставляемые интерфейсные платы с этим портом.
SCSI является потомком SASI (Shugart Assosiates System Interface-простой параллельной магистрали, которую фирма Shugart придумала для своих дисководов жестких дисков) и в простейшем виде представляет собой байтовый двунаправленный параллельный протокол с квитированием. Интерфейс обеспечивает несколько режимов, включая синхронную и асинхронную передачу с симметричными или несимметричными драйверами; хотя первоначально он использовался для связи единственного ЦП с единственным диском, однако с его помощью можно несколько ЦП подключить к нескольким дискам. Типичные скорости передачи составляют 1,5 Мбайт/с для асинхронного режима и 4 Мбайт/с для синхронного; асинхронный протокол медленнее, так как в процессе каждой пересылки туда и сюда передаются сигналы квитирования. С несимметричными драйверами SCSI обеспечивает передачу на 6 м, а с симметричными на 24 м.
Магистраль IEEE-488 (первоначально — интерфейс HPIB фирмы Hewlett-Packard) была разработана для подключения лабораторных приборов к компьютеру. Интерфейс включает полный протокол связи по магистрали нескольких приборов и использует терминологию локальных сетей. IEEE-488 занимает прочные позиции в инструментальной технике; фирмы Hewlett-Packard, Keithley, Philips/Fluke, Tektronix и Wavetek комплектуют этим интерфейсом большую часть выпускаемых ими приборов. Платы с интерфейсом IEEE-488 выпускаются почти для всех микрокомпьютеров. В разд. 10.20 мы еще вернемся к обсуждению интерфейсов SCSI и IEEE-488.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК